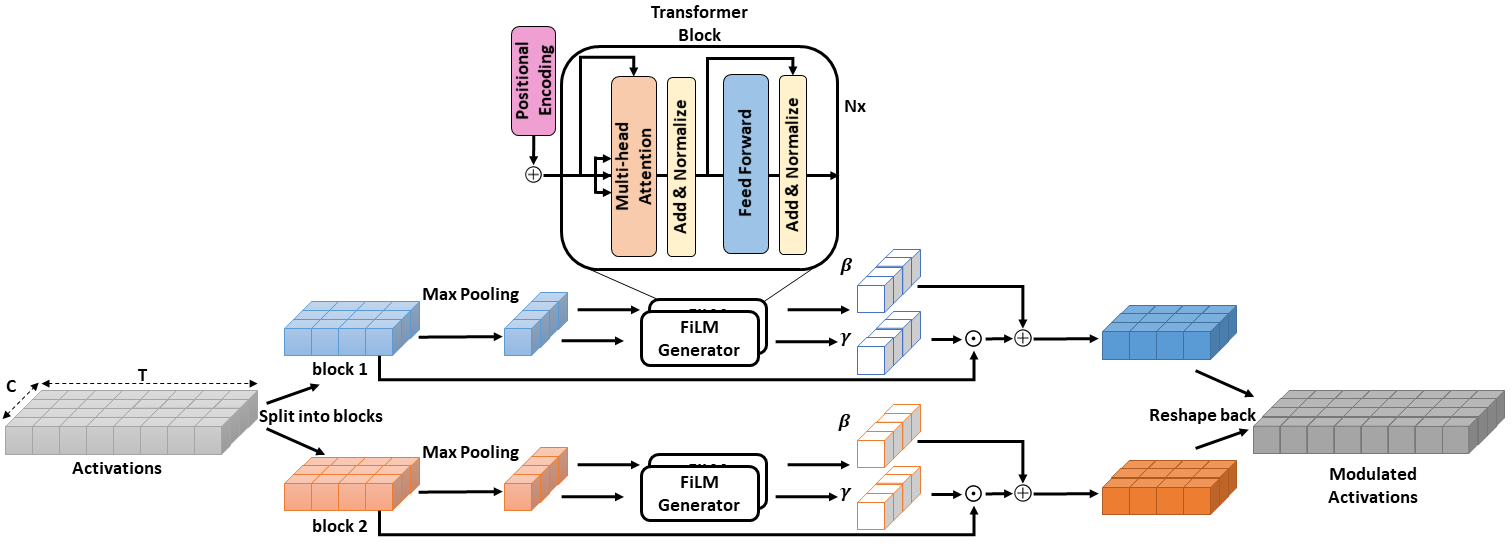
Self-Attention for Audio Super-Resolution
Convolutions operate only locally, thus failing to model global interactions. Self-attention is, however, able to learn representations that capture long-range dependencies in sequences. We propose a network architecture for audio super-resolution that combines convolution and self-attention. Attention-based Feature-Wise Linear Modulation (AFiLM) uses self-attention mechanism instead of recurrent neural networks to modulate the activations of the convolutional model. Extensive experiments show that our model outperforms existing approaches on standard benchmarks. Moreover, it allows for more parallelization resulting in significantly faster training.
PDF AbstractCode



Datasets
Results from the Paper
 Ranked #1 on
Audio Super-Resolution
on Voice Bank corpus (VCTK)
(using extra training data)
Ranked #1 on
Audio Super-Resolution
on Voice Bank corpus (VCTK)
(using extra training data)
