Self-Calibrated Efficient Transformer for Lightweight Super-Resolution
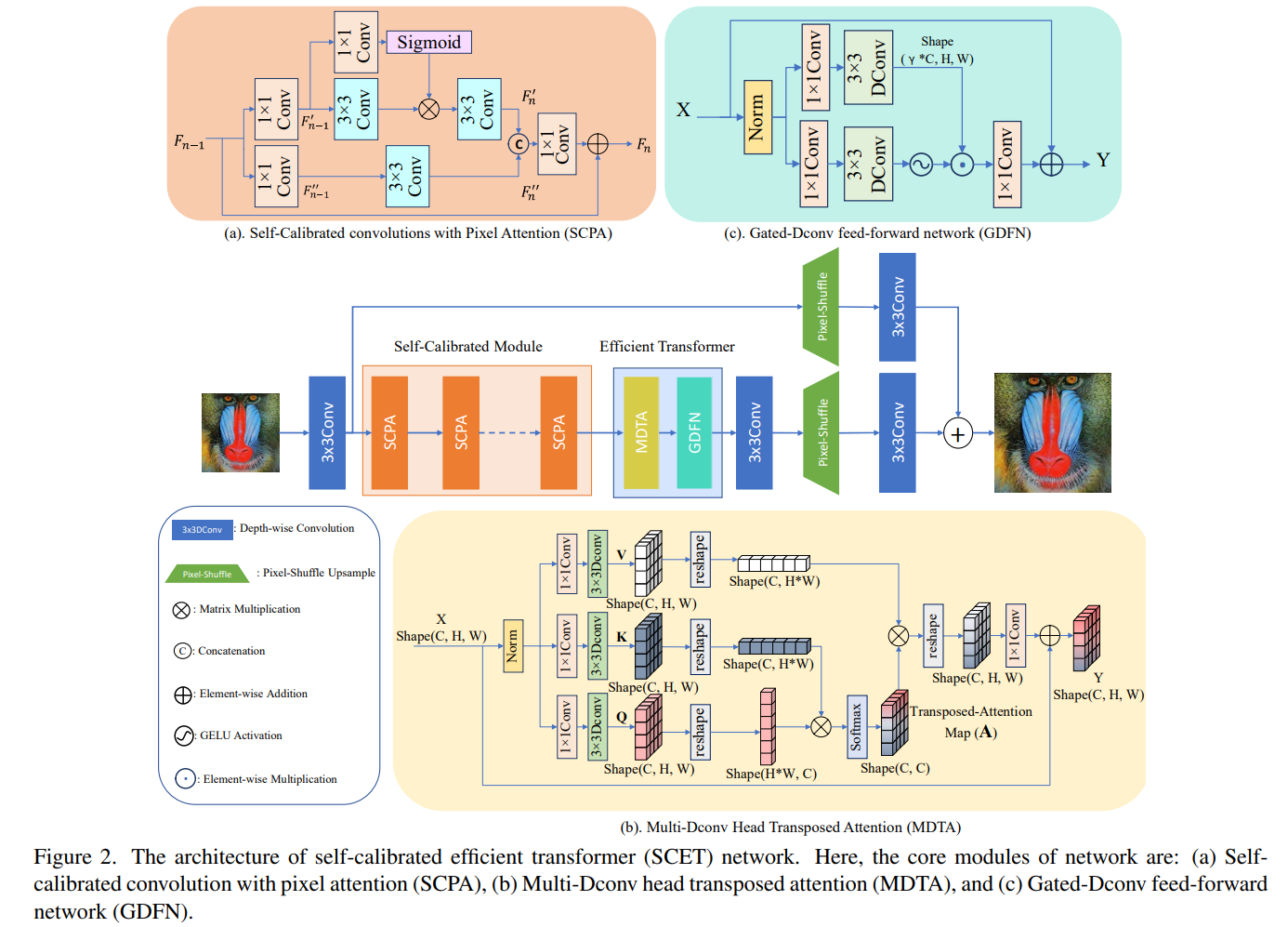
Recently, deep learning has been successfully applied to the single-image super-resolution (SISR) with remarkable performance. However, most existing methods focus on building a more complex network with a large number of layers, which can entail heavy computational costs and memory storage. To address this problem, we present a lightweight Self-Calibrated Efficient Transformer (SCET) network to solve this problem. The architecture of SCET mainly consists of the self-calibrated module and efficient transformer block, where the self-calibrated module adopts the pixel attention mechanism to extract image features effectively. To further exploit the contextual information from features, we employ an efficient transformer to help the network obtain similar features over long distances and thus recover sufficient texture details. We provide comprehensive results on different settings of the overall network. Our proposed method achieves more remarkable performance than baseline methods. The source code and pre-trained models are available at https://github.com/AlexZou14/SCET.
PDF Abstract


 Set14
Set14
 Set5
Set5
 Manga109
Manga109
