Self-PU: Self Boosted and Calibrated Positive-Unlabeled Training
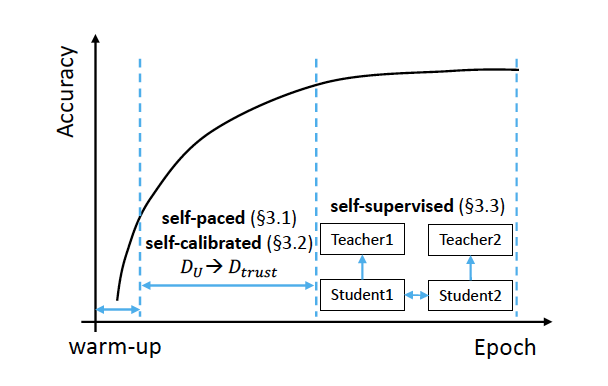
Many real-world applications have to tackle the Positive-Unlabeled (PU) learning problem, i.e., learning binary classifiers from a large amount of unlabeled data and a few labeled positive examples. While current state-of-the-art methods employ importance reweighting to design various risk estimators, they ignored the learning capability of the model itself, which could have provided reliable supervision. This motivates us to propose a novel Self-PU learning framework, which seamlessly integrates PU learning and self-training. Self-PU highlights three "self"-oriented building blocks: a self-paced training algorithm that adaptively discovers and augments confident positive/negative examples as the training proceeds; a self-calibrated instance-aware loss; and a self-distillation scheme that introduces teacher-students learning as an effective regularization for PU learning. We demonstrate the state-of-the-art performance of Self-PU on common PU learning benchmarks (MNIST and CIFAR-10), which compare favorably against the latest competitors. Moreover, we study a real-world application of PU learning, i.e., classifying brain images of Alzheimer's Disease. Self-PU obtains significantly improved results on the renowned Alzheimer's Disease Neuroimaging Initiative (ADNI) database over existing methods. The code is publicly available at: https://github.com/TAMU-VITA/Self-PU.
PDF Abstract ICML 2020 PDF
