| TASK |
DATASET |
MODEL |
METRIC NAME |
METRIC VALUE |
GLOBAL RANK |
REMOVE |
|
Audio Classification
|
DCASE
|
CrissCross (AudioSet)
|
Top-1 Accuracy
|
97
|
# 1
|
|
|
Audio Classification
|
DCASE
|
CrissCross (AudioSet)
|
PRE-TRAINING DATASET
|
AudioSet
|
# 1
|
|
|
Audio Classification
|
DCASE
|
CrissCross (Kinetics-400)
|
Top-1 Accuracy
|
96
|
# 2
|
|
|
Audio Classification
|
DCASE
|
CrissCross (Kinetics-400)
|
PRE-TRAINING DATASET
|
Kinetics-400
|
# 1
|
|
|
Audio Classification
|
DCASE
|
CrissCross (Kinetics-Sound)
|
Top-1 Accuracy
|
93
|
# 5
|
|
|
Audio Classification
|
DCASE
|
CrissCross (Kinetics-Sound)
|
PRE-TRAINING DATASET
|
Kinetics-Sound
|
# 1
|
|
|
Self-Supervised Audio Classification
|
ESC-50
|
CrissCross (AudioSet)
|
Top-1 Accuracy
|
90.5
|
# 2
|
|
|
Self-Supervised Audio Classification
|
ESC-50
|
CrissCross (Kinetics400)
|
Top-1 Accuracy
|
86.8
|
# 4
|
|
|
Self-Supervised Action Recognition
|
HMDB51
|
CrissCross (Kinetics-Sound)
|
Top-1 Accuracy
|
60.5
|
# 26
|
|
|
Self-Supervised Action Recognition
|
HMDB51
|
CrissCross (Kinetics-Sound)
|
Pre-Training Dataset
|
Kinetics-Sound
|
# 1
|
|
|
Self-Supervised Action Recognition
|
HMDB51
|
CrissCross (Kinetics-Sound)
|
Frozen
|
false
|
# 1
|
|
|
Self-supervised Video Retrieval
|
HMDB51
|
CrissCross (R2+1D)
|
Top-1
|
26.4
|
# 6
|
|
|
Self-supervised Video Retrieval
|
HMDB51
|
CrissCross (R2+1D)
|
Pretrain
|
Kinetics400
|
# 1
|
|
|
Self-Supervised Action Recognition
|
HMDB51
|
CrissCross (AudioSet)
|
Top-1 Accuracy
|
66.8
|
# 11
|
|
|
Self-Supervised Action Recognition
|
HMDB51
|
CrissCross (AudioSet)
|
Pre-Training Dataset
|
AudioSet
|
# 1
|
|
|
Self-Supervised Action Recognition
|
HMDB51
|
CrissCross (AudioSet)
|
Frozen
|
false
|
# 1
|
|
|
Self-Supervised Action Recognition
|
HMDB51
|
CrissCross (Kinetics400)
|
Top-1 Accuracy
|
64.7
|
# 16
|
|
|
Self-Supervised Action Recognition
|
HMDB51
|
CrissCross (Kinetics400)
|
Pre-Training Dataset
|
Kinetics400
|
# 1
|
|
|
Self-Supervised Action Recognition
|
HMDB51
|
CrissCross (Kinetics400)
|
Frozen
|
false
|
# 1
|
|
|
Self-Supervised Action Recognition
|
UCF101
|
CrissCross (Kinetics400)
|
3-fold Accuracy
|
91.5
|
# 18
|
|
|
Self-Supervised Action Recognition
|
UCF101
|
CrissCross (Kinetics400)
|
Pre-Training Dataset
|
Kinetics400
|
# 1
|
|
|
Self-Supervised Action Recognition
|
UCF101
|
CrissCross (Kinetics400)
|
Frozen
|
false
|
# 1
|
|
|
Self-Supervised Action Recognition
|
UCF101
|
CrissCross (Kinetics-Sound)
|
3-fold Accuracy
|
88.3
|
# 25
|
|
|
Self-Supervised Action Recognition
|
UCF101
|
CrissCross (Kinetics-Sound)
|
Pre-Training Dataset
|
Kinetics-Sound
|
# 1
|
|
|
Self-Supervised Action Recognition
|
UCF101
|
CrissCross (Kinetics-Sound)
|
Frozen
|
false
|
# 1
|
|
|
Self-supervised Video Retrieval
|
UCF101
|
CrissCross (R2+1D)
|
Top-1
|
63.8
|
# 5
|
|
|
Self-supervised Video Retrieval
|
UCF101
|
CrissCross (R2+1D)
|
Pretrain
|
Kinetics400
|
# 1
|
|
|
Self-Supervised Action Recognition
|
UCF101
|
CrissCross (AudioSet)
|
3-fold Accuracy
|
92.4
|
# 16
|
|
|
Self-Supervised Action Recognition
|
UCF101
|
CrissCross (AudioSet)
|
Pre-Training Dataset
|
AudioSet
|
# 1
|
|
|
Self-Supervised Action Recognition
|
UCF101
|
CrissCross (AudioSet)
|
Frozen
|
false
|
# 1
|
|
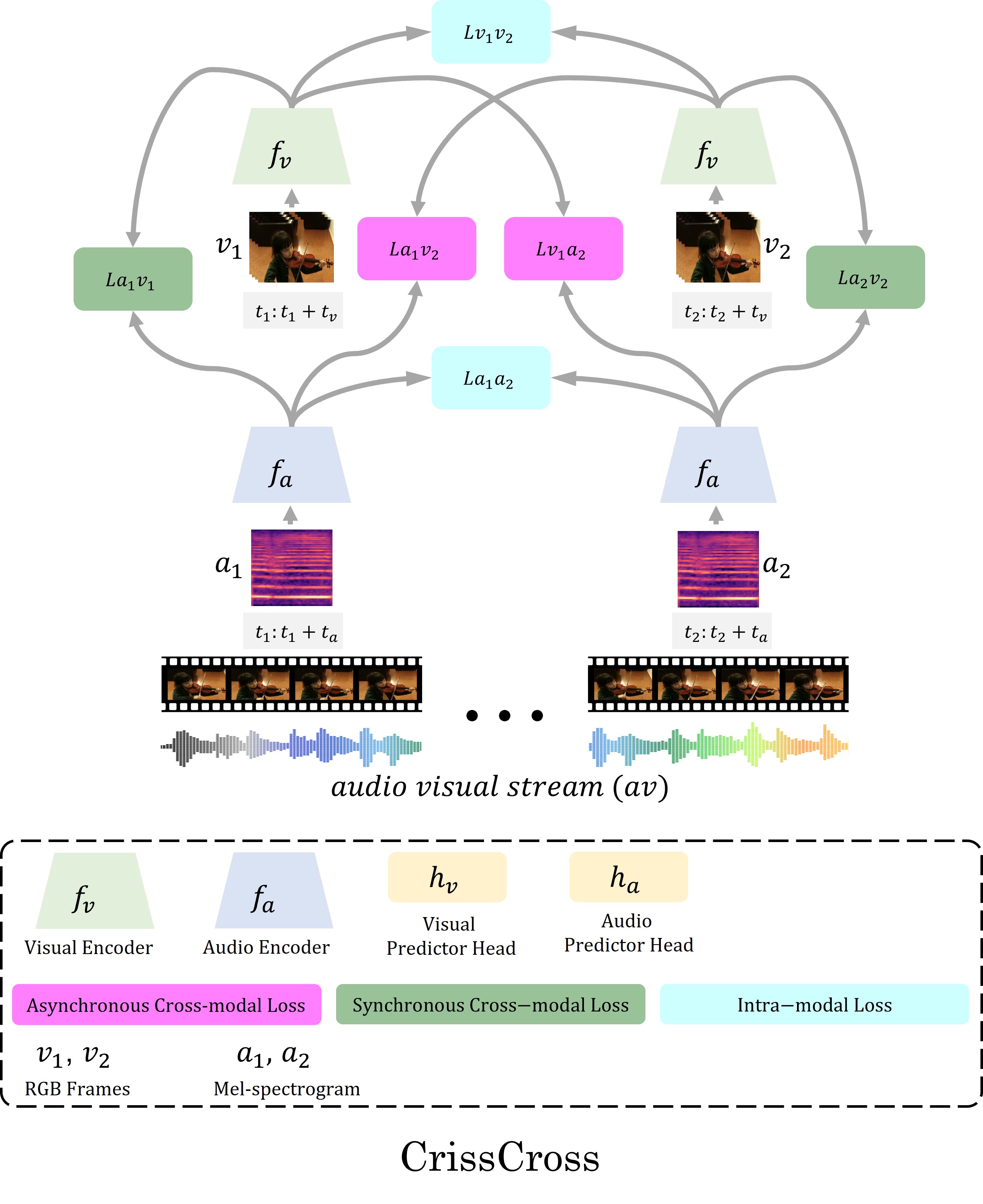



 UCF101
UCF101
 Kinetics
Kinetics
 HMDB51
HMDB51
 Kinetics 400
Kinetics 400
 AudioSet
AudioSet
 ESC-50
ESC-50
 DCASE 2017
DCASE 2017

