Self-supervised learning using consistency regularization of spatio-temporal data augmentation for action recognition
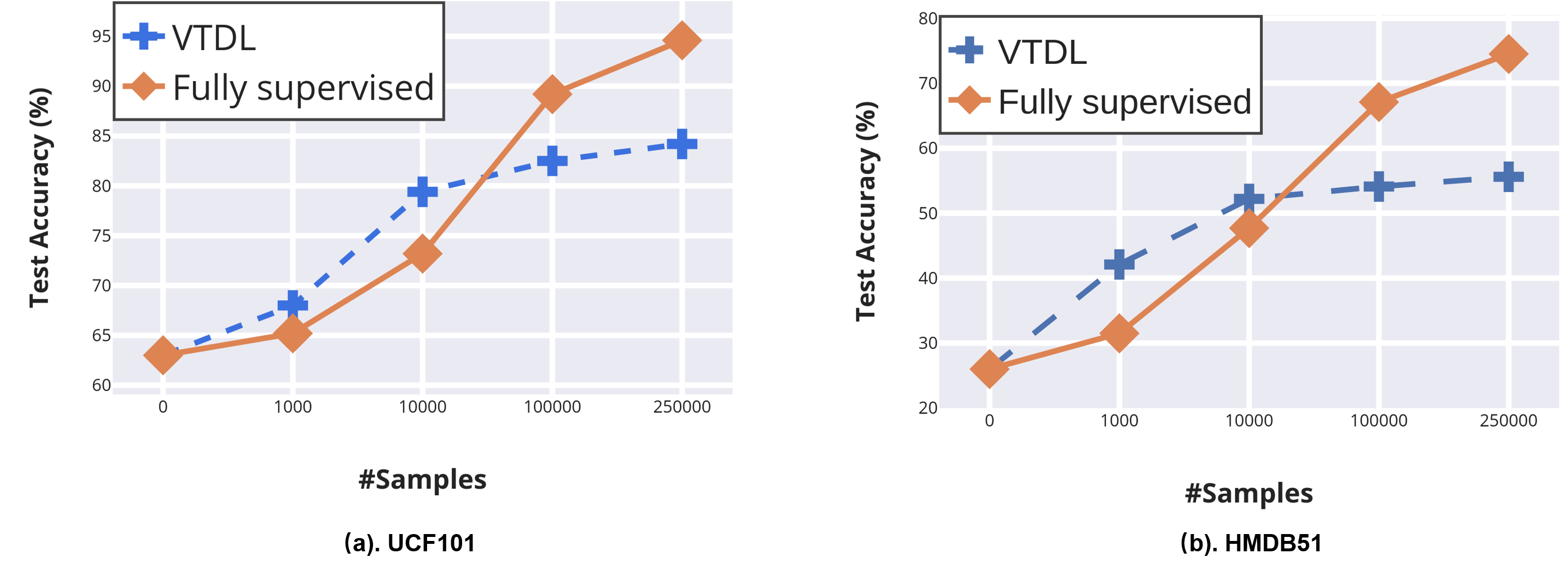
Self-supervised learning has shown great potentials in improving the deep learning model in an unsupervised manner by constructing surrogate supervision signals directly from the unlabeled data. Different from existing works, we present a novel way to obtain the surrogate supervision signal based on high-level feature maps under consistency regularization. In this paper, we propose a Spatio-Temporal Consistency Regularization between different output features generated from a siamese network including a clean path fed with original video and a noise path fed with the corresponding augmented video. Based on the Spatio-Temporal characteristics of video, we develop two video-based data augmentation methods, i.e., Spatio-Temporal Transformation and Intra-Video Mixup. Consistency of the former one is proposed to model transformation consistency of features, while the latter one aims at retaining spatial invariance to extract action-related features. Extensive experiments demonstrate that our method achieves substantial improvements compared with state-of-the-art self-supervised learning methods for action recognition. When using our method as an additional regularization term and combine with current surrogate supervision signals, we achieve 22% relative improvement over the previous state-of-the-art on HMDB51 and 7% on UCF101.
PDF Abstract



 UCF101
UCF101
