Self-supervised Multi-view Stereo via Effective Co-Segmentation and Data-Augmentation
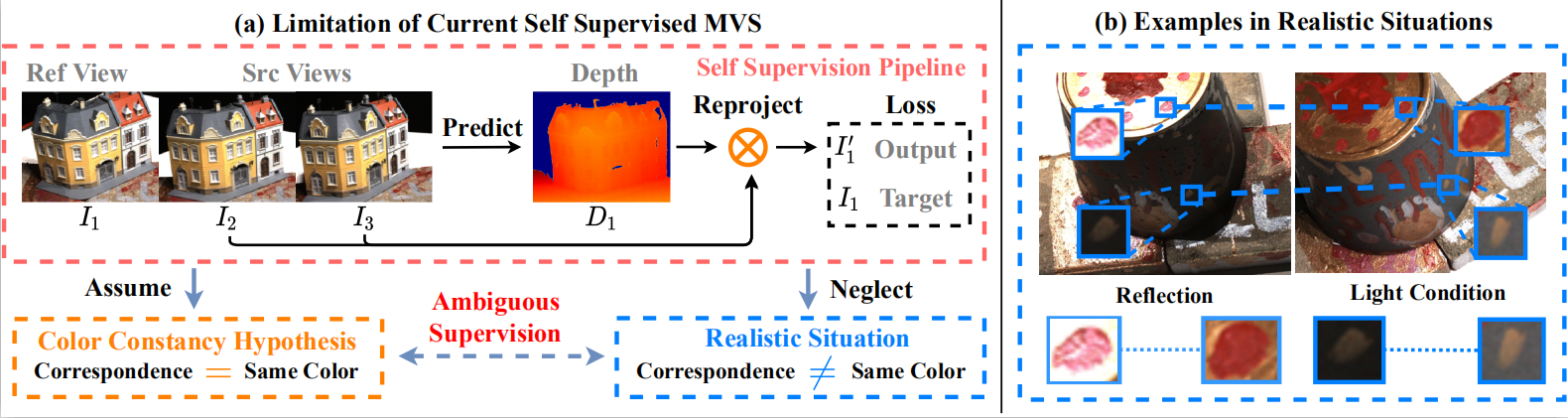
Recent studies have witnessed that self-supervised methods based on view synthesis obtain clear progress on multi-view stereo (MVS). However, existing methods rely on the assumption that the corresponding points among different views share the same color, which may not always be true in practice. This may lead to unreliable self-supervised signal and harm the final reconstruction performance. To address the issue, we propose a framework integrated with more reliable supervision guided by semantic co-segmentation and data-augmentation. Specially, we excavate mutual semantic from multi-view images to guide the semantic consistency. And we devise effective data-augmentation mechanism which ensures the transformation robustness by treating the prediction of regular samples as pseudo ground truth to regularize the prediction of augmented samples. Experimental results on DTU dataset show that our proposed methods achieve the state-of-the-art performance among unsupervised methods, and even compete on par with supervised methods. Furthermore, extensive experiments on Tanks&Temples dataset demonstrate the effective generalization ability of the proposed method.
PDF Abstract

