Self-Supervised Scene De-occlusion
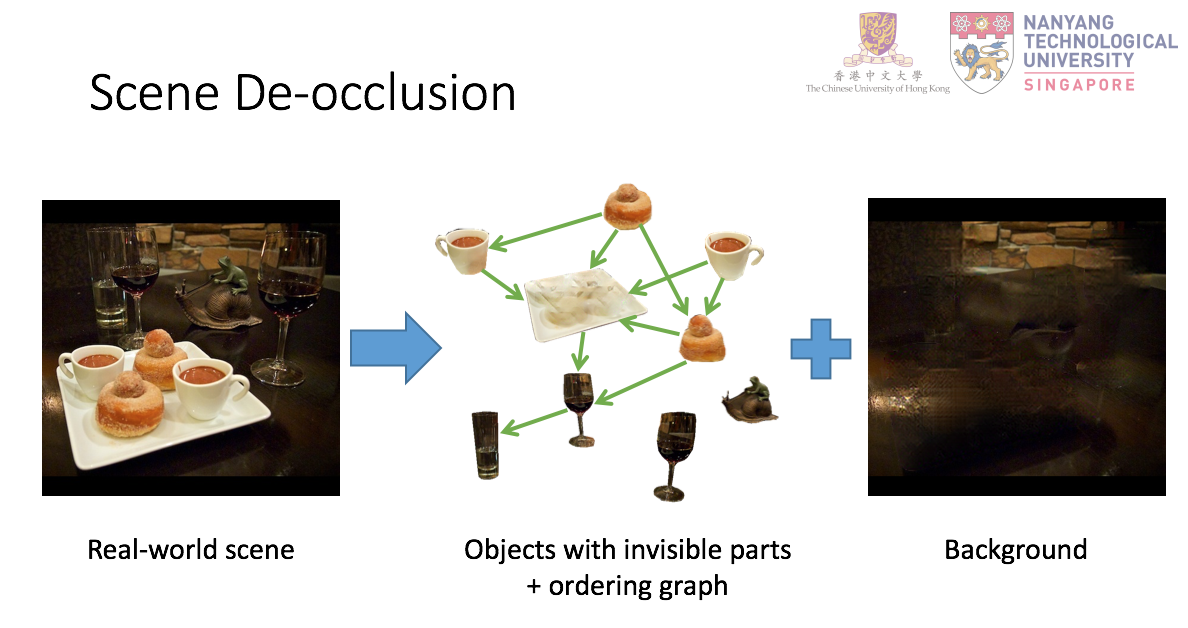
Natural scene understanding is a challenging task, particularly when encountering images of multiple objects that are partially occluded. This obstacle is given rise by varying object ordering and positioning. Existing scene understanding paradigms are able to parse only the visible parts, resulting in incomplete and unstructured scene interpretation. In this paper, we investigate the problem of scene de-occlusion, which aims to recover the underlying occlusion ordering and complete the invisible parts of occluded objects. We make the first attempt to address the problem through a novel and unified framework that recovers hidden scene structures without ordering and amodal annotations as supervisions. This is achieved via Partial Completion Network (PCNet)-mask (M) and -content (C), that learn to recover fractions of object masks and contents, respectively, in a self-supervised manner. Based on PCNet-M and PCNet-C, we devise a novel inference scheme to accomplish scene de-occlusion, via progressive ordering recovery, amodal completion and content completion. Extensive experiments on real-world scenes demonstrate the superior performance of our approach to other alternatives. Remarkably, our approach that is trained in a self-supervised manner achieves comparable results to fully-supervised methods. The proposed scene de-occlusion framework benefits many applications, including high-quality and controllable image manipulation and scene recomposition (see Fig. 1), as well as the conversion of existing modal mask annotations to amodal mask annotations.
PDF Abstract CVPR 2020 PDF CVPR 2020 Abstract

 MS COCO
MS COCO
