Self-supervised Video Representation Learning Using Inter-intra Contrastive Framework
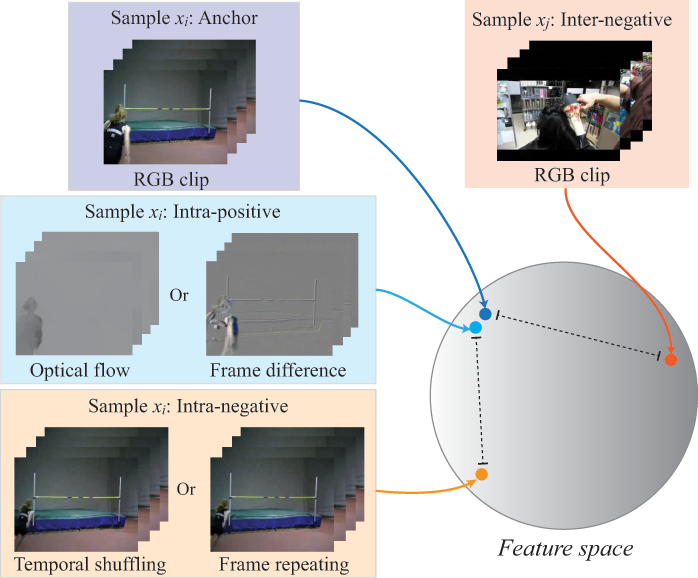
We propose a self-supervised method to learn feature representations from videos. A standard approach in traditional self-supervised methods uses positive-negative data pairs to train with contrastive learning strategy. In such a case, different modalities of the same video are treated as positives and video clips from a different video are treated as negatives. Because the spatio-temporal information is important for video representation, we extend the negative samples by introducing intra-negative samples, which are transformed from the same anchor video by breaking temporal relations in video clips. With the proposed Inter-Intra Contrastive (IIC) framework, we can train spatio-temporal convolutional networks to learn video representations. There are many flexible options in our IIC framework and we conduct experiments by using several different configurations. Evaluations are conducted on video retrieval and video recognition tasks using the learned video representation. Our proposed IIC outperforms current state-of-the-art results by a large margin, such as 16.7% and 9.5% points improvements in top-1 accuracy on UCF101 and HMDB51 datasets for video retrieval, respectively. For video recognition, improvements can also be obtained on these two benchmark datasets. Code is available at https://github.com/BestJuly/Inter-intra-video-contrastive-learning.
PDF Abstract



 UCF101
UCF101
 Kinetics
Kinetics
 HMDB51
HMDB51

