Self-Supervised Vision Transformers Learn Visual Concepts in Histopathology
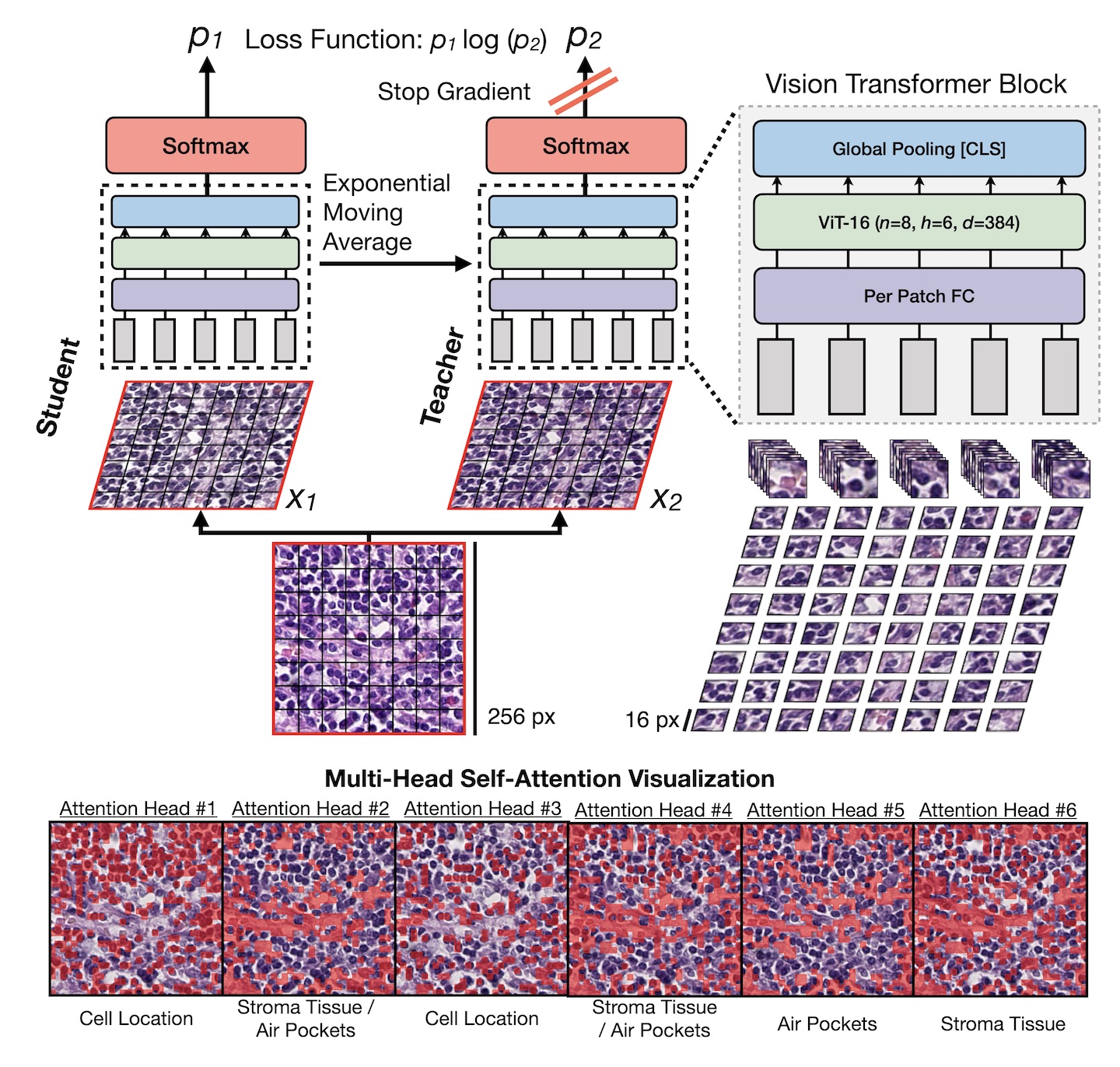
Tissue phenotyping is a fundamental task in learning objective characterizations of histopathologic biomarkers within the tumor-immune microenvironment in cancer pathology. However, whole-slide imaging (WSI) is a complex computer vision in which: 1) WSIs have enormous image resolutions with precludes large-scale pixel-level efforts in data curation, and 2) diversity of morphological phenotypes results in inter- and intra-observer variability in tissue labeling. To address these limitations, current efforts have proposed using pretrained image encoders (transfer learning from ImageNet, self-supervised pretraining) in extracting morphological features from pathology, but have not been extensively validated. In this work, we conduct a search for good representations in pathology by training a variety of self-supervised models with validation on a variety of weakly-supervised and patch-level tasks. Our key finding is in discovering that Vision Transformers using DINO-based knowledge distillation are able to learn data-efficient and interpretable features in histology images wherein the different attention heads learn distinct morphological phenotypes. We make evaluation code and pretrained weights publicly-available at: https://github.com/Richarizardd/Self-Supervised-ViT-Path.
PDF Abstract


 ImageNet
ImageNet
