Semantic Frame Forecast
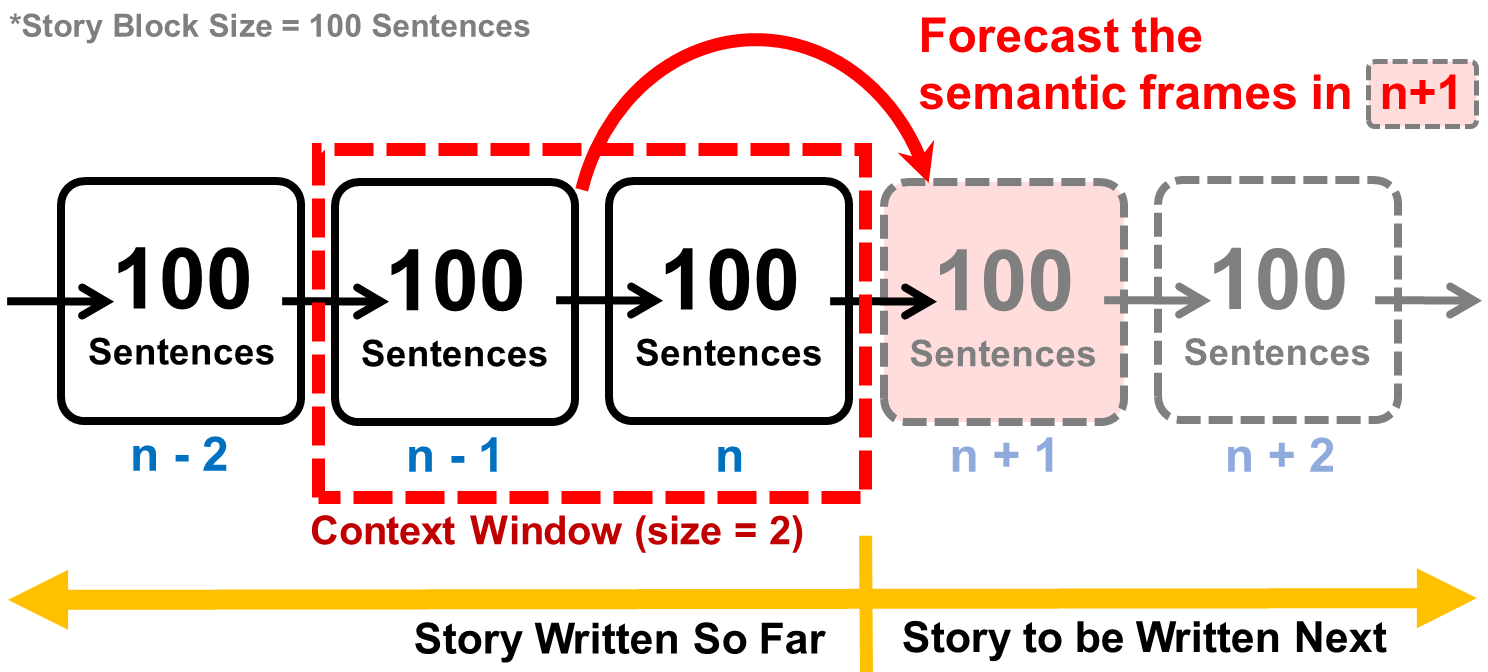
This paper introduces semantic frame forecast, a task that predicts the semantic frames that will occur in the next 10, 100, or even 1,000 sentences in a running story. Prior work focused on predicting the immediate future of a story, such as one to a few sentences ahead. However, when novelists write long stories, generating a few sentences is not enough to help them gain high-level insight to develop the follow-up story. In this paper, we formulate a long story as a sequence of "story blocks," where each block contains a fixed number of sentences (e.g., 10, 100, or 200). This formulation allows us to predict the follow-up story arc beyond the scope of a few sentences. We represent a story block using the term frequencies (TF) of semantic frames in it, normalized by each frame's inverse document frequency (IDF). We conduct semantic frame forecast experiments on 4,794 books from the Bookcorpus and 7,962 scientific abstracts from CODA-19, with block sizes ranging from 5 to 1,000 sentences. The results show that automated models can forecast the follow-up story blocks better than the random, prior, and replay baselines, indicating the task's feasibility. We also learn that the models using the frame representation as features outperform all the existing approaches when the block size is over 150 sentences. The human evaluation also shows that the proposed frame representation, when visualized as word clouds, is comprehensible, representative, and specific to humans. Our code is available at https://github.com/appleternity/FrameForecasting.
PDF Abstract NAACL 2021 PDF NAACL 2021 Abstract
 FrameNet
FrameNet
 BookCorpus
BookCorpus
 CODA-19
CODA-19
