Separate but Together: Unsupervised Federated Learning for Speech Enhancement from Non-IID Data
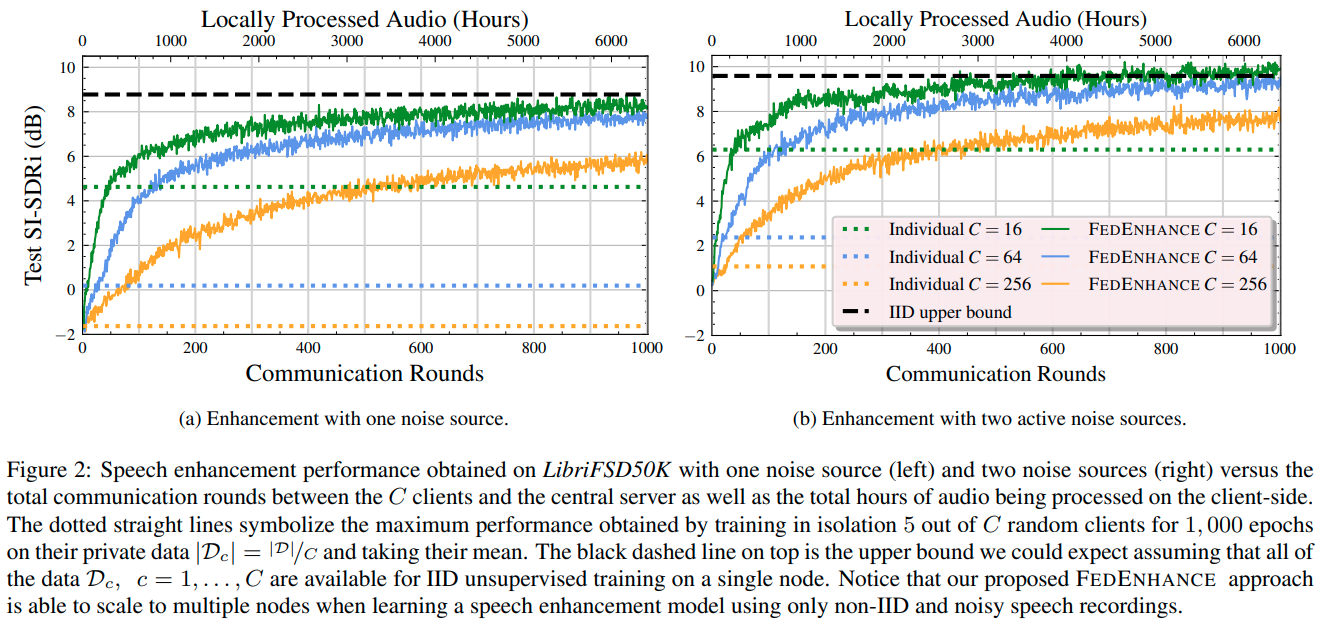
We propose FEDENHANCE, an unsupervised federated learning (FL) approach for speech enhancement and separation with non-IID distributed data across multiple clients. We simulate a real-world scenario where each client only has access to a few noisy recordings from a limited and disjoint number of speakers (hence non-IID). Each client trains their model in isolation using mixture invariant training while periodically providing updates to a central server. Our experiments show that our approach achieves competitive enhancement performance compared to IID training on a single device and that we can further facilitate the convergence speed and the overall performance using transfer learning on the server-side. Moreover, we show that we can effectively combine updates from clients trained locally with supervised and unsupervised losses. We also release a new dataset LibriFSD50K and its creation recipe in order to facilitate FL research for source separation problems.
PDF Abstract



 LibriSpeech
LibriSpeech
 FSD50K
FSD50K
