Separating Skills and Concepts for Novel Visual Question Answering
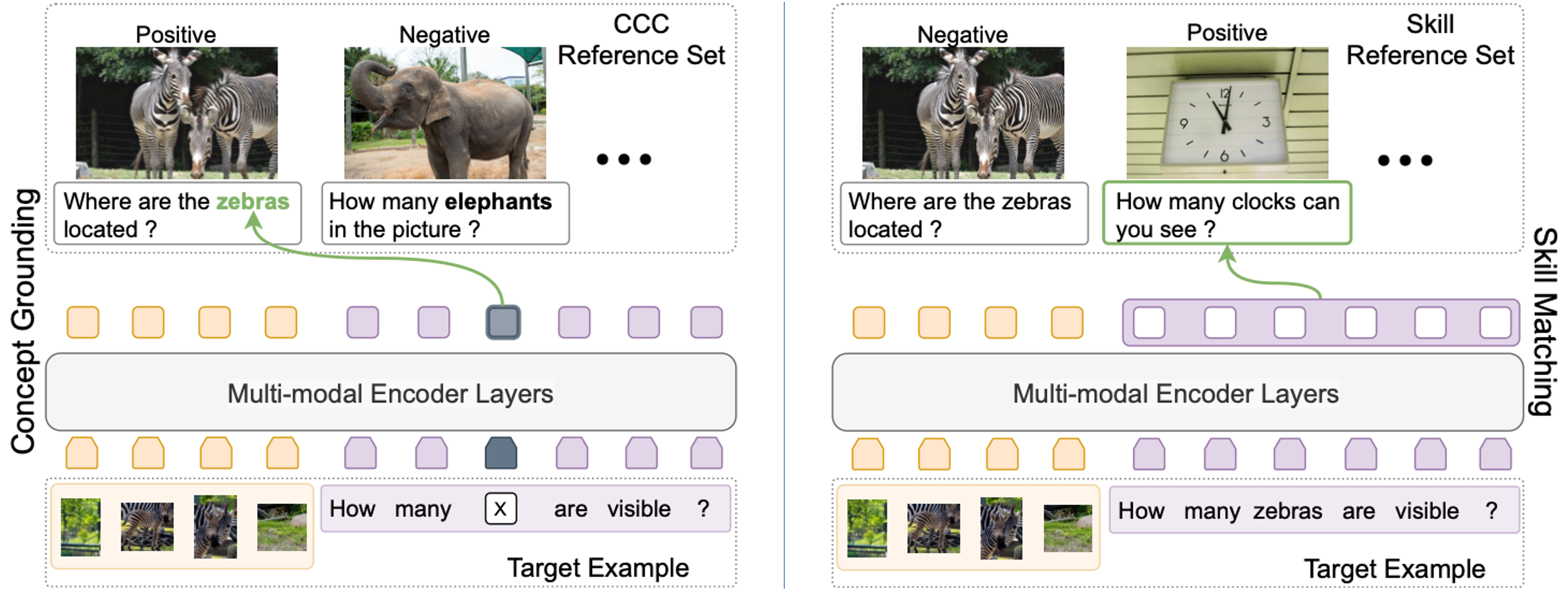
Generalization to out-of-distribution data has been a problem for Visual Question Answering (VQA) models. To measure generalization to novel questions, we propose to separate them into "skills" and "concepts". "Skills" are visual tasks, such as counting or attribute recognition, and are applied to "concepts" mentioned in the question, such as objects and people. VQA methods should be able to compose skills and concepts in novel ways, regardless of whether the specific composition has been seen in training, yet we demonstrate that existing models have much to improve upon towards handling new compositions. We present a novel method for learning to compose skills and concepts that separates these two factors implicitly within a model by learning grounded concept representations and disentangling the encoding of skills from that of concepts. We enforce these properties with a novel contrastive learning procedure that does not rely on external annotations and can be learned from unlabeled image-question pairs. Experiments demonstrate the effectiveness of our approach for improving compositional and grounding performance.
PDF Abstract CVPR 2021 PDF CVPR 2021 Abstract




 Visual Question Answering
Visual Question Answering
 CLEVR
CLEVR
 GQA
GQA
 Visual Question Answering v2.0
Visual Question Answering v2.0
 TextVQA
TextVQA
