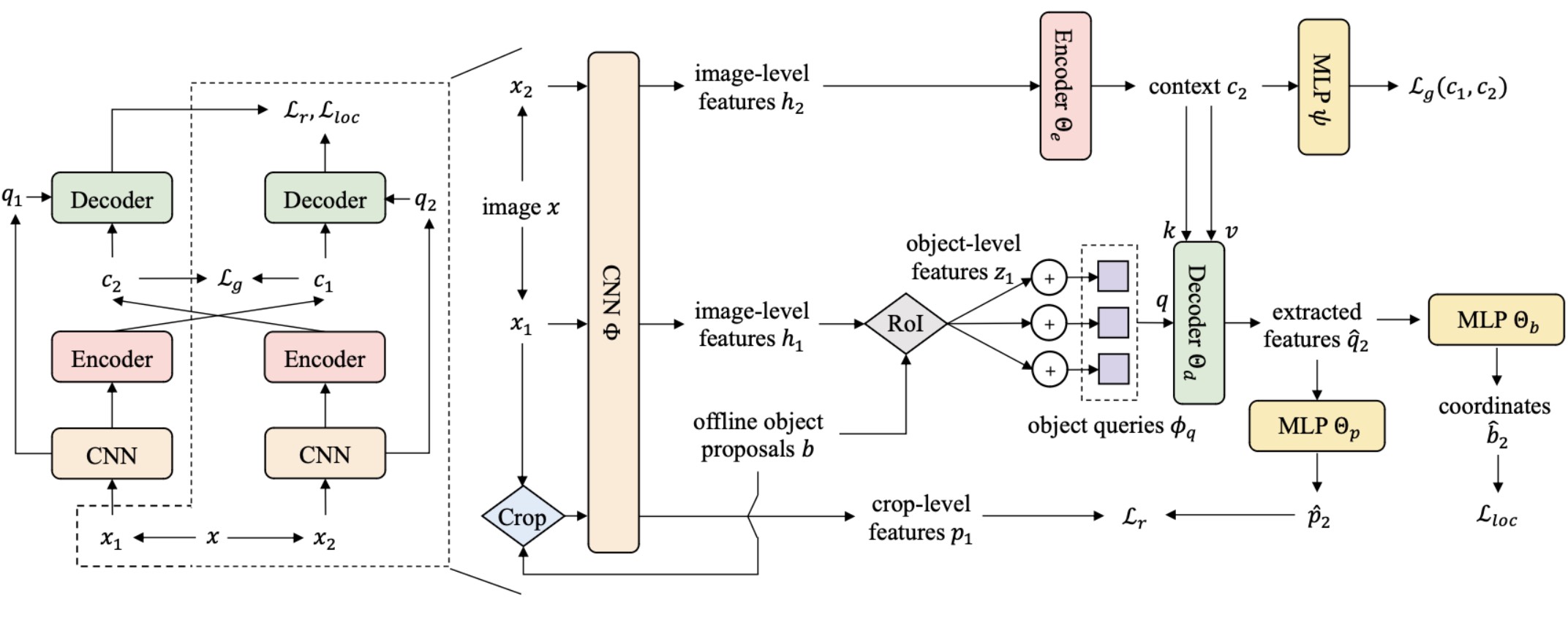
Siamese DETR
Recent self-supervised methods are mainly designed for representation learning with the base model, e.g., ResNets or ViTs. They cannot be easily transferred to DETR, with task-specific Transformer modules. In this work, we present Siamese DETR, a Siamese self-supervised pretraining approach for the Transformer architecture in DETR. We consider learning view-invariant and detection-oriented representations simultaneously through two complementary tasks, i.e., localization and discrimination, in a novel multi-view learning framework. Two self-supervised pretext tasks are designed: (i) Multi-View Region Detection aims at learning to localize regions-of-interest between augmented views of the input, and (ii) Multi-View Semantic Discrimination attempts to improve object-level discrimination for each region. The proposed Siamese DETR achieves state-of-the-art transfer performance on COCO and PASCAL VOC detection using different DETR variants in all setups. Code is available at https://github.com/Zx55/SiameseDETR.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract


 ImageNet
ImageNet
 MS COCO
MS COCO
