SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization
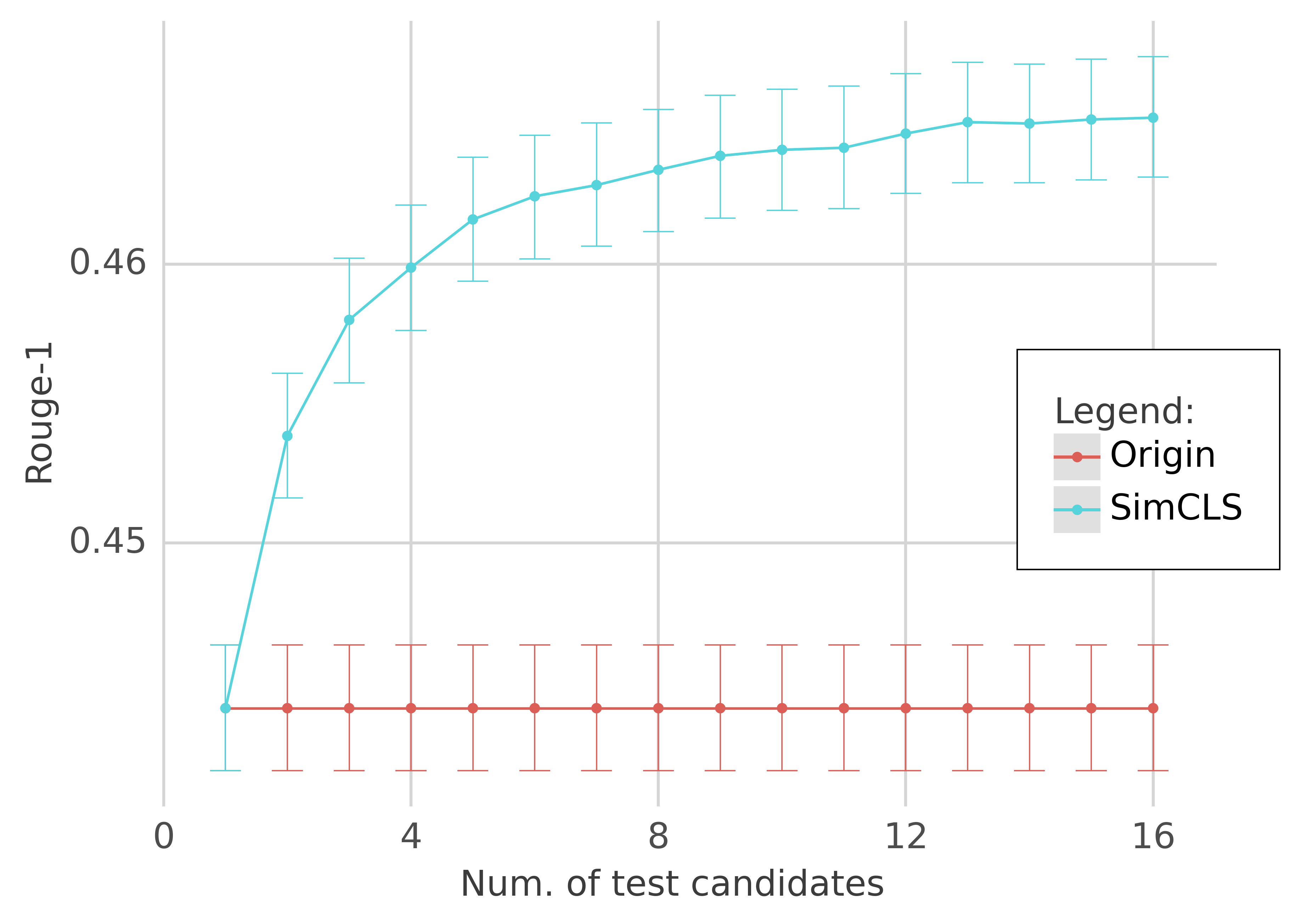
In this paper, we present a conceptually simple while empirically powerful framework for abstractive summarization, SimCLS, which can bridge the gap between the learning objective and evaluation metrics resulting from the currently dominated sequence-to-sequence learning framework by formulating text generation as a reference-free evaluation problem (i.e., quality estimation) assisted by contrastive learning. Experimental results show that, with minor modification over existing top-scoring systems, SimCLS can improve the performance of existing top-performing models by a large margin. Particularly, 2.51 absolute improvement against BART and 2.50 over PEGASUS w.r.t ROUGE-1 on the CNN/DailyMail dataset, driving the state-of-the-art performance to a new level. We have open-sourced our codes and results: https://github.com/yixinL7/SimCLS. Results of our proposed models have been deployed into ExplainaBoard platform, which allows researchers to understand our systems in a more fine-grained way.
PDF Abstract ACL 2021 PDF ACL 2021 AbstractCode

 Colab
Colab




Datasets
 CNN/Daily Mail
CNN/Daily Mail
 XSum
XSum

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Abstractive Text Summarization | CNN / Daily Mail | BART + SimCLS | ROUGE-1 | 46.67 | # 6 | |
| ROUGE-2 | 22.15 | # 5 | ||||
| ROUGE-L | 43.54 | # 6 | ||||
| Text Summarization | X-Sum | PEGASUS + SimCLS | ROUGE-1 | 47.61 | # 4 | |
| ROUGE-2 | 24.57 | # 4 | ||||
| ROUGE-L | 39.44 | # 2 |
