Similarity-Aware Fusion Network for 3D Semantic Segmentation
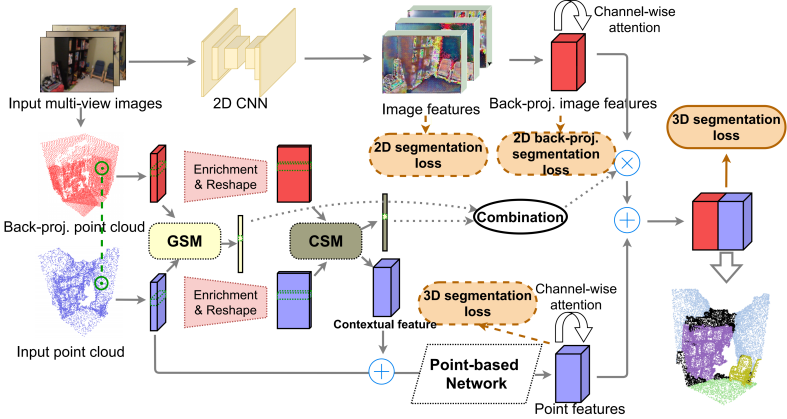
In this paper, we propose a similarity-aware fusion network (SAFNet) to adaptively fuse 2D images and 3D point clouds for 3D semantic segmentation. Existing fusion-based methods achieve remarkable performances by integrating information from multiple modalities. However, they heavily rely on the correspondence between 2D pixels and 3D points by projection and can only perform the information fusion in a fixed manner, and thus their performances cannot be easily migrated to a more realistic scenario where the collected data often lack strict pair-wise features for prediction. To address this, we employ a late fusion strategy where we first learn the geometric and contextual similarities between the input and back-projected (from 2D pixels) point clouds and utilize them to guide the fusion of two modalities to further exploit complementary information. Specifically, we employ a geometric similarity module (GSM) to directly compare the spatial coordinate distributions of pair-wise 3D neighborhoods, and a contextual similarity module (CSM) to aggregate and compare spatial contextual information of corresponding central points. The two proposed modules can effectively measure how much image features can help predictions, enabling the network to adaptively adjust the contributions of two modalities to the final prediction of each point. Experimental results on the ScanNetV2 benchmark demonstrate that SAFNet significantly outperforms existing state-of-the-art fusion-based approaches across various data integrity.
PDF Abstract


 ScanNet
ScanNet

