Simple Hardware-Efficient Long Convolutions for Sequence Modeling
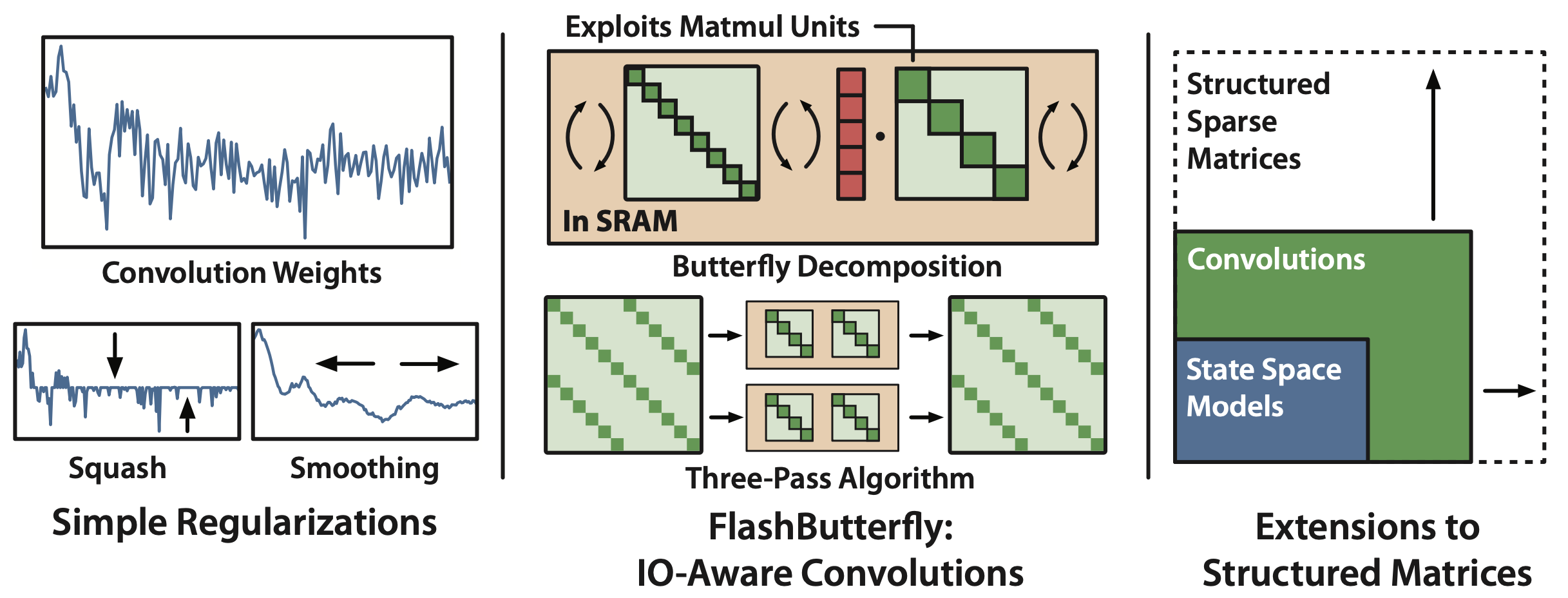
State space models (SSMs) have high performance on long sequence modeling but require sophisticated initialization techniques and specialized implementations for high quality and runtime performance. We study whether a simple alternative can match SSMs in performance and efficiency: directly learning long convolutions over the sequence. We find that a key requirement to achieving high performance is keeping the convolution kernels smooth. We find that simple interventions--such as squashing the kernel weights--result in smooth kernels and recover SSM performance on a range of tasks including the long range arena, image classification, language modeling, and brain data modeling. Next, we develop FlashButterfly, an IO-aware algorithm to improve the runtime performance of long convolutions. FlashButterfly appeals to classic Butterfly decompositions of the convolution to reduce GPU memory IO and increase FLOP utilization. FlashButterfly speeds up convolutions by 2.2$\times$, and allows us to train on Path256, a challenging task with sequence length 64K, where we set state-of-the-art by 29.1 points while training 7.2$\times$ faster than prior work. Lastly, we introduce an extension to FlashButterfly that learns the coefficients of the Butterfly decomposition, increasing expressivity without increasing runtime. Using this extension, we outperform a Transformer on WikiText103 by 0.2 PPL with 30% fewer parameters.
PDF Abstract


 The Pile
The Pile
