Simulated Multiple Reference Training Improves Low-Resource Machine Translation
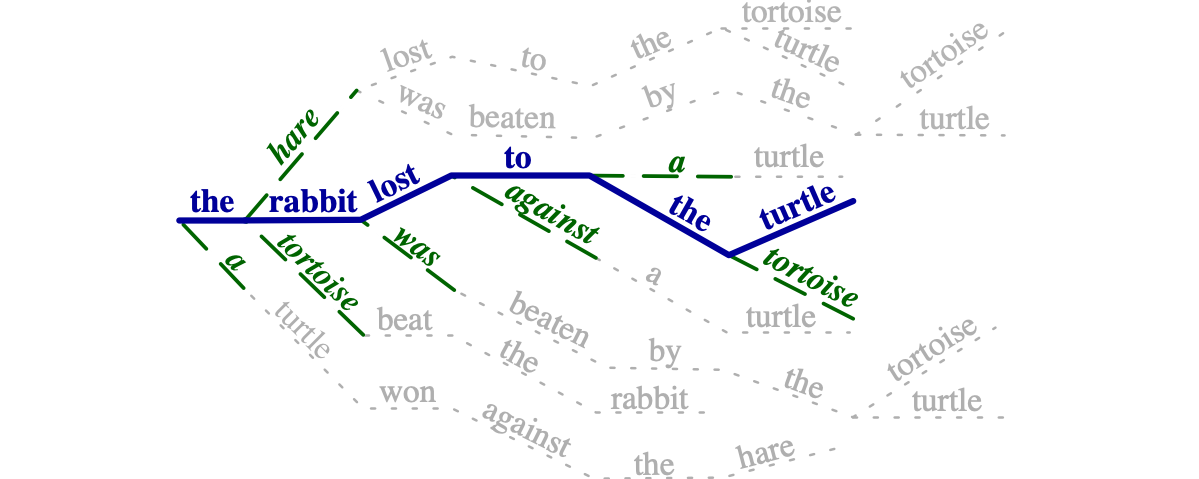
Many valid translations exist for a given sentence, yet machine translation (MT) is trained with a single reference translation, exacerbating data sparsity in low-resource settings. We introduce Simulated Multiple Reference Training (SMRT), a novel MT training method that approximates the full space of possible translations by sampling a paraphrase of the reference sentence from a paraphraser and training the MT model to predict the paraphraser's distribution over possible tokens. We demonstrate the effectiveness of SMRT in low-resource settings when translating to English, with improvements of 1.2 to 7.0 BLEU. We also find SMRT is complementary to back-translation.
PDF Abstract EMNLP 2020 PDF EMNLP 2020 AbstractCode



Datasets
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
