Single-Shot Motion Completion with Transformer
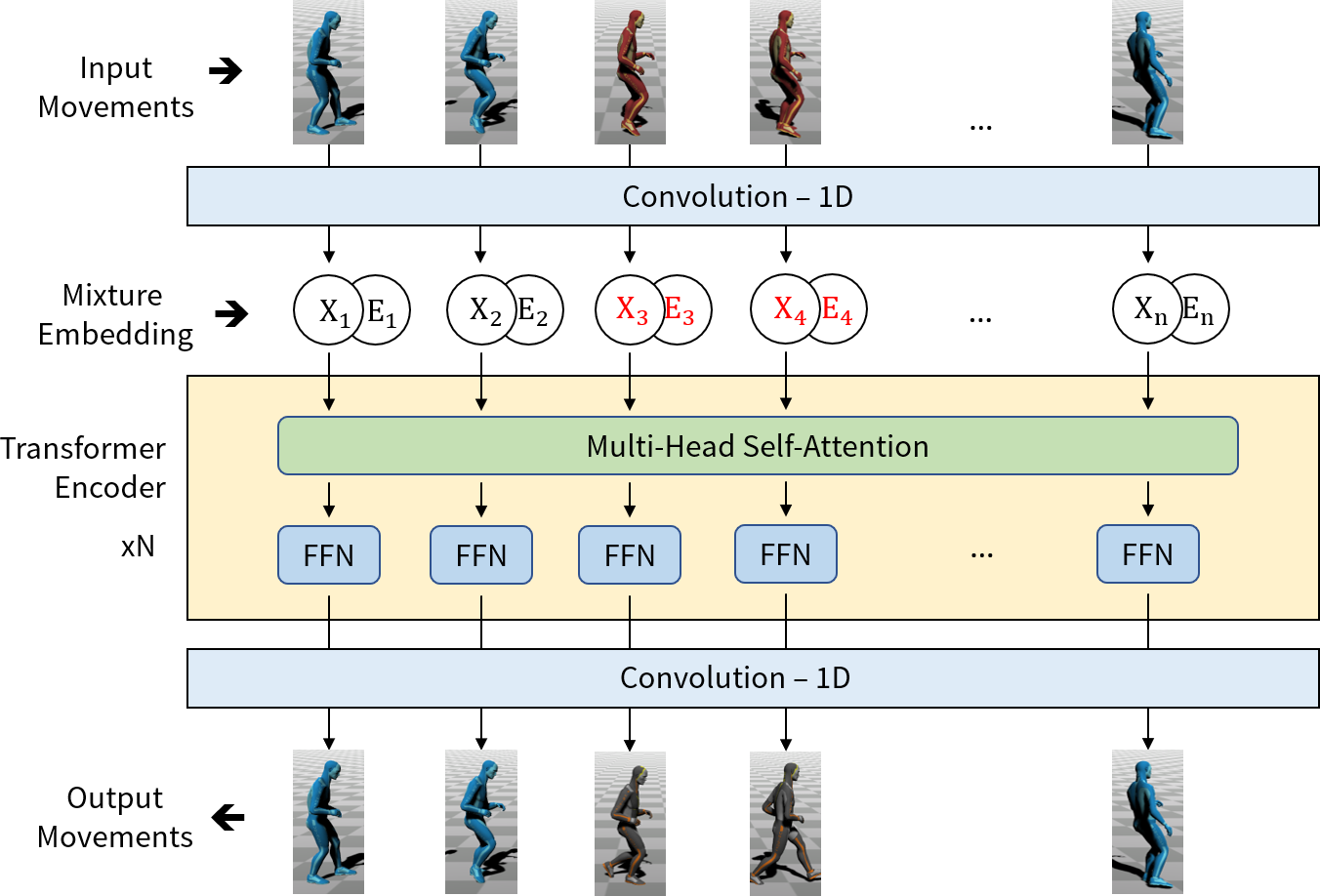
Motion completion is a challenging and long-discussed problem, which is of great significance in film and game applications. For different motion completion scenarios (in-betweening, in-filling, and blending), most previous methods deal with the completion problems with case-by-case designs. In this work, we propose a simple but effective method to solve multiple motion completion problems under a unified framework and achieves a new state of the art accuracy under multiple evaluation settings. Inspired by the recent great success of attention-based models, we consider the completion as a sequence to sequence prediction problem. Our method consists of two modules - a standard transformer encoder with self-attention that learns long-range dependencies of input motions, and a trainable mixture embedding module that models temporal information and discriminates key-frames. Our method can run in a non-autoregressive manner and predict multiple missing frames within a single forward propagation in real time. We finally show the effectiveness of our method in music-dance applications.
PDF Abstract
 LaFAN1
LaFAN1

