Sinkhorn Label Allocation: Semi-Supervised Classification via Annealed Self-Training
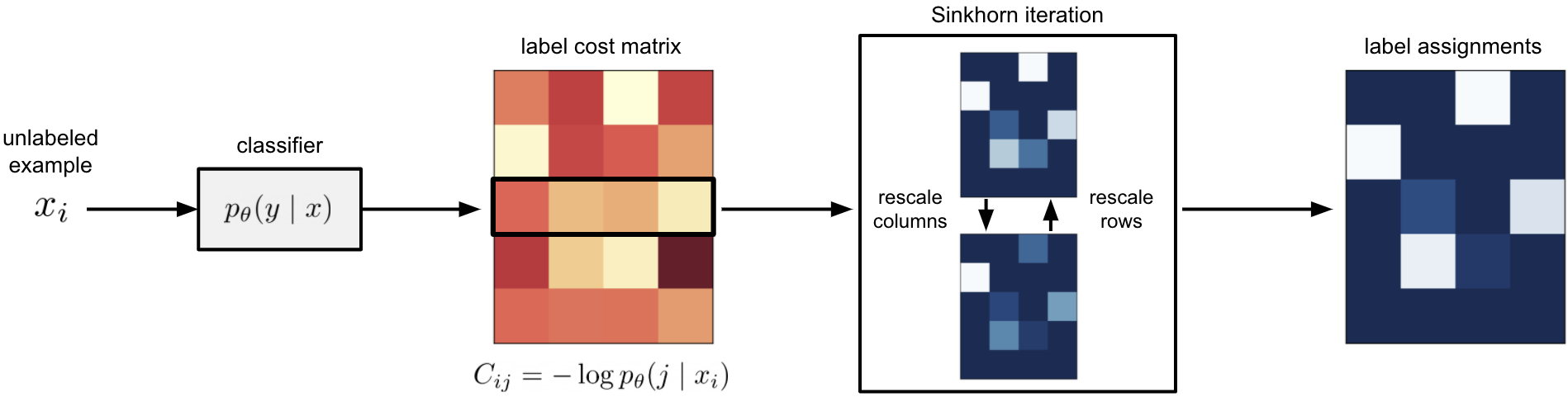
Self-training is a standard approach to semi-supervised learning where the learner's own predictions on unlabeled data are used as supervision during training. In this paper, we reinterpret this label assignment process as an optimal transportation problem between examples and classes, wherein the cost of assigning an example to a class is mediated by the current predictions of the classifier. This formulation facilitates a practical annealing strategy for label assignment and allows for the inclusion of prior knowledge on class proportions via flexible upper bound constraints. The solutions to these assignment problems can be efficiently approximated using Sinkhorn iteration, thus enabling their use in the inner loop of standard stochastic optimization algorithms. We demonstrate the effectiveness of our algorithm on the CIFAR-10, CIFAR-100, and SVHN datasets in comparison with FixMatch, a state-of-the-art self-training algorithm. Our code is available at https://github.com/stanford-futuredata/sinkhorn-label-allocation.
PDF Abstract



 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 SVHN
SVHN
