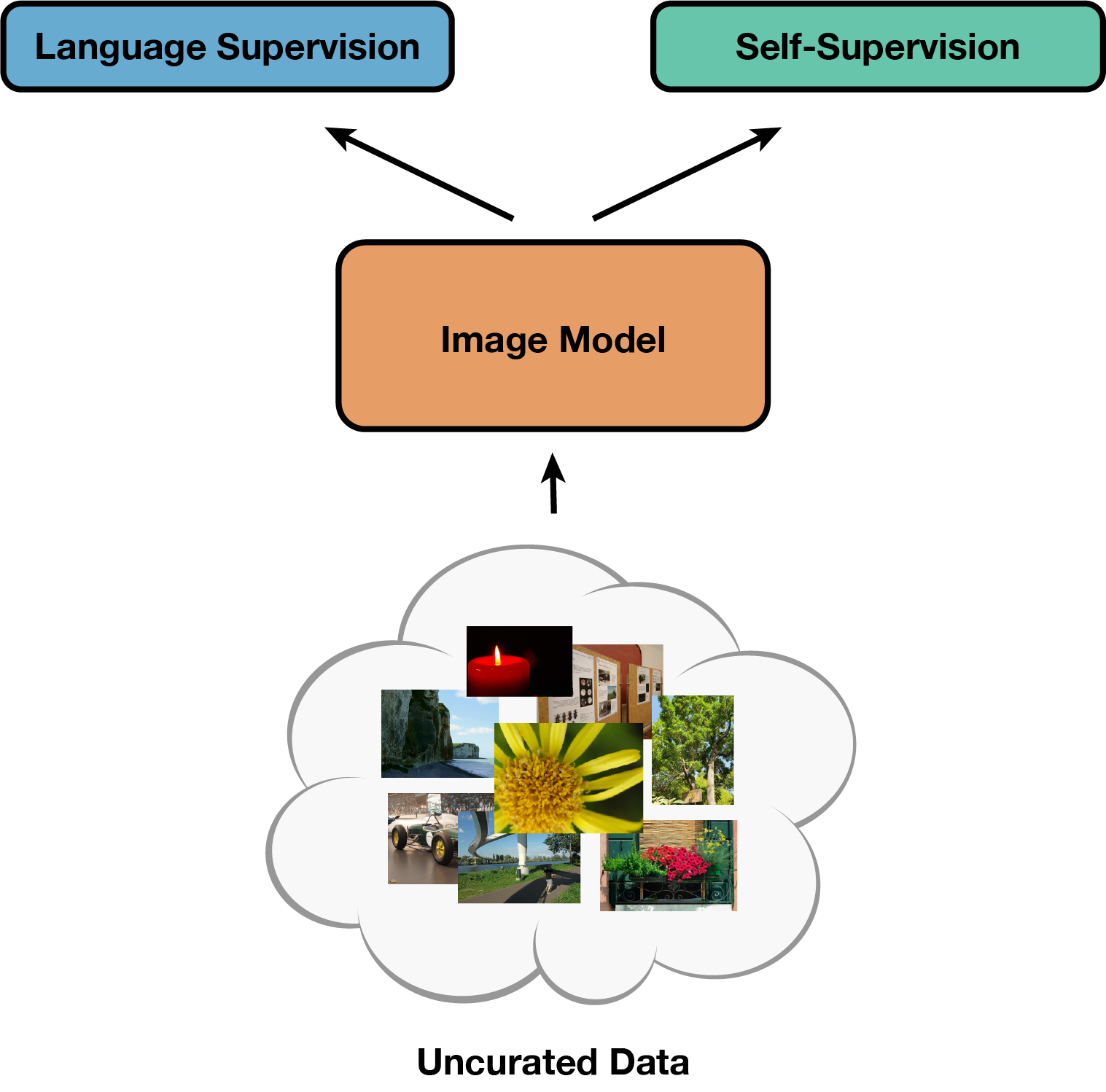
SLIP: Self-supervision meets Language-Image Pre-training
Recent work has shown that self-supervised pre-training leads to improvements over supervised learning on challenging visual recognition tasks. CLIP, an exciting new approach to learning with language supervision, demonstrates promising performance on a wide variety of benchmarks. In this work, we explore whether self-supervised learning can aid in the use of language supervision for visual representation learning. We introduce SLIP, a multi-task learning framework for combining self-supervised learning and CLIP pre-training. After pre-training with Vision Transformers, we thoroughly evaluate representation quality and compare performance to both CLIP and self-supervised learning under three distinct settings: zero-shot transfer, linear classification, and end-to-end finetuning. Across ImageNet and a battery of additional datasets, we find that SLIP improves accuracy by a large margin. We validate our results further with experiments on different model sizes, training schedules, and pre-training datasets. Our findings show that SLIP enjoys the best of both worlds: better performance than self-supervision (+8.1% linear accuracy) and language supervision (+5.2% zero-shot accuracy).
PDF Abstract



 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 MNIST
MNIST
 KITTI
KITTI
 SST
SST
 CUB-200-2011
CUB-200-2011
 STL-10
STL-10
 Food-101
Food-101
 YFCC100M
YFCC100M
 PCam
PCam
