Sparse evolutionary Deep Learning with over one million artificial neurons on commodity hardware
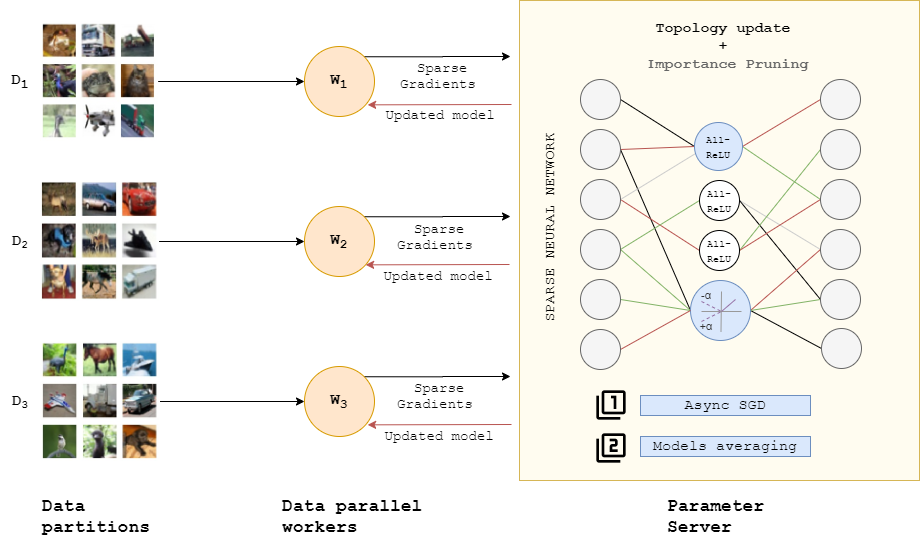
Artificial Neural Networks (ANNs) have emerged as hot topics in the research community. Despite the success of ANNs, it is challenging to train and deploy modern ANNs on commodity hardware due to the ever-increasing model size and the unprecedented growth in the data volumes. Particularly for microarray data, the very-high dimensionality and the small number of samples make it difficult for machine learning techniques to handle. Furthermore, specialized hardware such as Graphics Processing Unit (GPU) is expensive. Sparse neural networks are the leading approaches to address these challenges. However, off-the-shelf sparsity inducing techniques either operate from a pre-trained model or enforce the sparse structure via binary masks. The training efficiency of sparse neural networks cannot be obtained practically. In this paper, we introduce a technique allowing us to train truly sparse neural networks with fixed parameter count throughout training. Our experimental results demonstrate that our method can be applied directly to handle high dimensional data, while achieving higher accuracy than the traditional two phases approaches. Moreover, we have been able to create truly sparse MultiLayer Perceptrons (MLPs) models with over one million neurons and to train them on a typical laptop without GPU, this being way beyond what is possible with any state-of-the-art techniques.
PDF Abstract
