Sparsely Aggregated Convolutional Networks
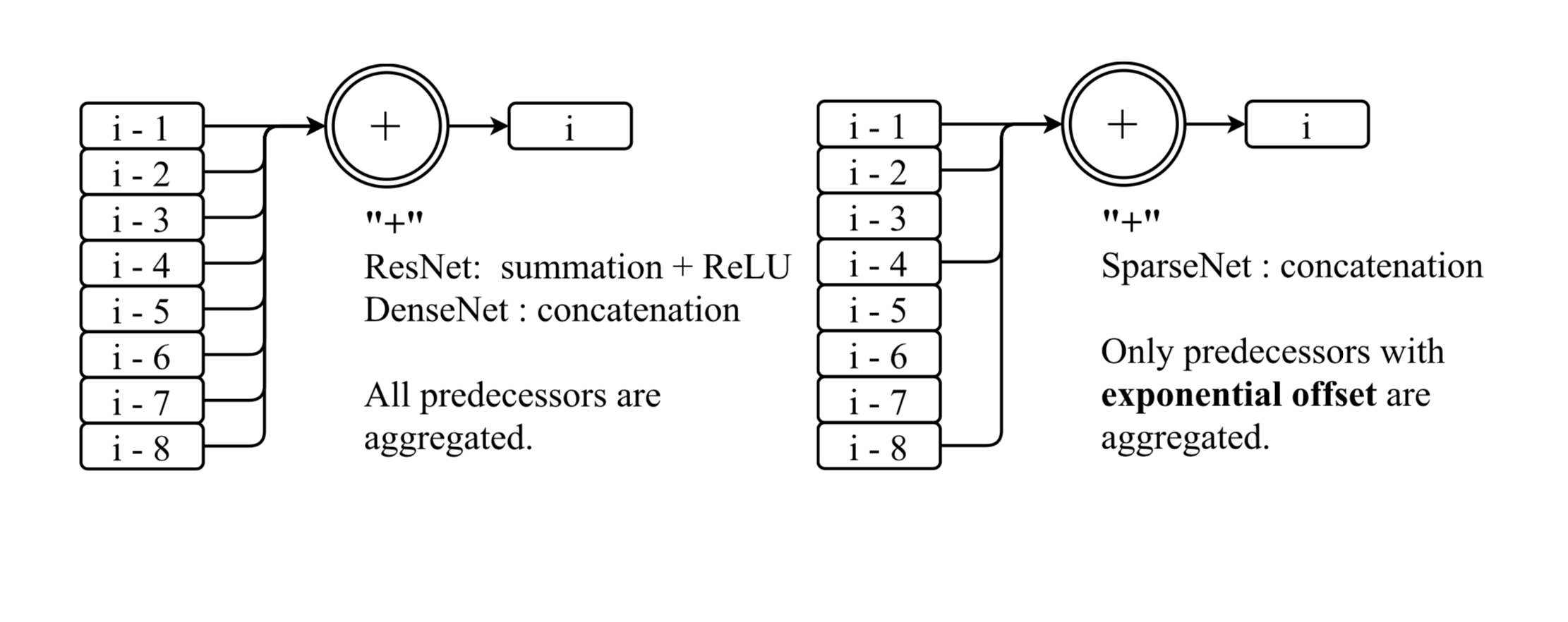
We explore a key architectural aspect of deep convolutional neural networks: the pattern of internal skip connections used to aggregate outputs of earlier layers for consumption by deeper layers. Such aggregation is critical to facilitate training of very deep networks in an end-to-end manner. This is a primary reason for the widespread adoption of residual networks, which aggregate outputs via cumulative summation. While subsequent works investigate alternative aggregation operations (e.g. concatenation), we focus on an orthogonal question: which outputs to aggregate at a particular point in the network. We propose a new internal connection structure which aggregates only a sparse set of previous outputs at any given depth. Our experiments demonstrate this simple design change offers superior performance with fewer parameters and lower computational requirements. Moreover, we show that sparse aggregation allows networks to scale more robustly to 1000+ layers, thereby opening future avenues for training long-running visual processes.
PDF Abstract ECCV 2018 PDF ECCV 2018 Abstract

 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
