Spatial As Deep: Spatial CNN for Traffic Scene Understanding
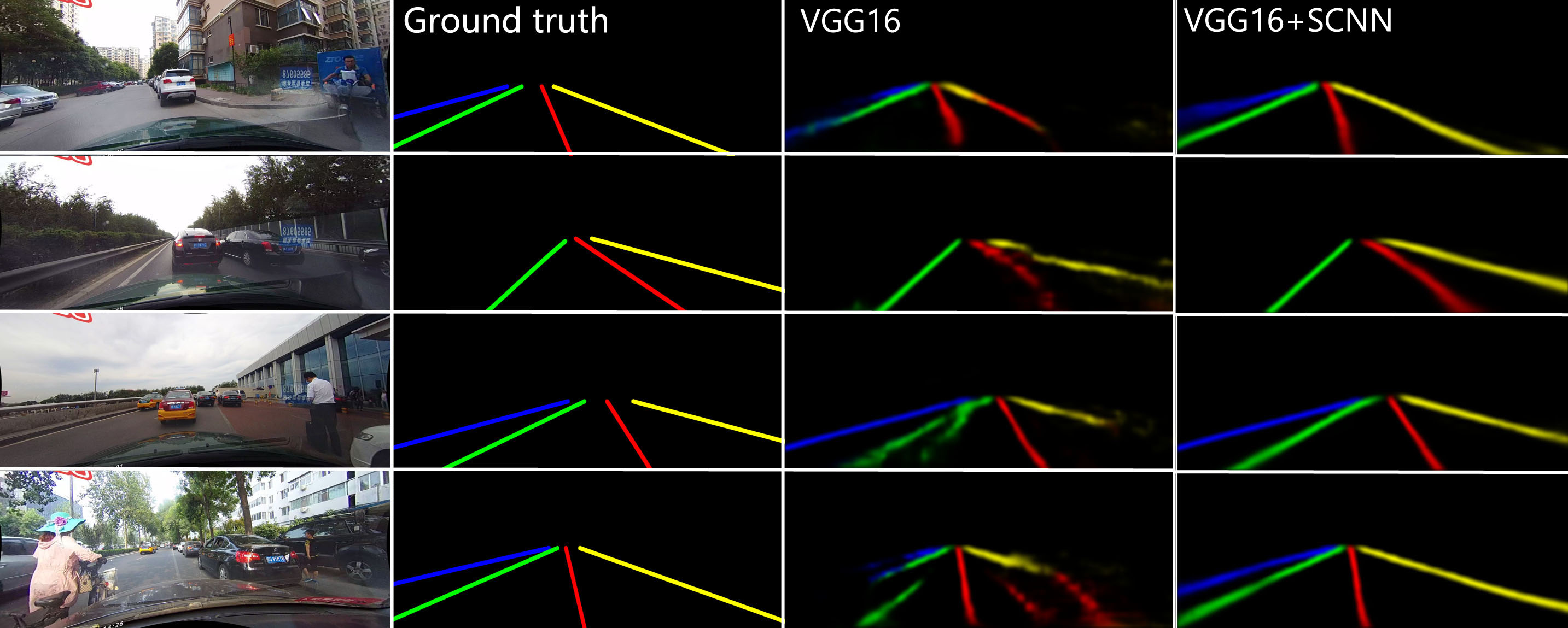
Convolutional neural networks (CNNs) are usually built by stacking convolutional operations layer-by-layer. Although CNN has shown strong capability to extract semantics from raw pixels, its capacity to capture spatial relationships of pixels across rows and columns of an image is not fully explored. These relationships are important to learn semantic objects with strong shape priors but weak appearance coherences, such as traffic lanes, which are often occluded or not even painted on the road surface as shown in Fig. 1 (a). In this paper, we propose Spatial CNN (SCNN), which generalizes traditional deep layer-by-layer convolutions to slice-byslice convolutions within feature maps, thus enabling message passings between pixels across rows and columns in a layer. Such SCNN is particular suitable for long continuous shape structure or large objects, with strong spatial relationship but less appearance clues, such as traffic lanes, poles, and wall. We apply SCNN on a newly released very challenging traffic lane detection dataset and Cityscapse dataset. The results show that SCNN could learn the spatial relationship for structure output and significantly improves the performance. We show that SCNN outperforms the recurrent neural network (RNN) based ReNet and MRF+CNN (MRFNet) in the lane detection dataset by 8.7% and 4.6% respectively. Moreover, our SCNN won the 1st place on the TuSimple Benchmark Lane Detection Challenge, with an accuracy of 96.53%.
PDF Abstract





 CULane
CULane
 Cityscapes
Cityscapes
 TuSimple
TuSimple

