Skeleton-based Action Recognition via Spatial and Temporal Transformer Networks
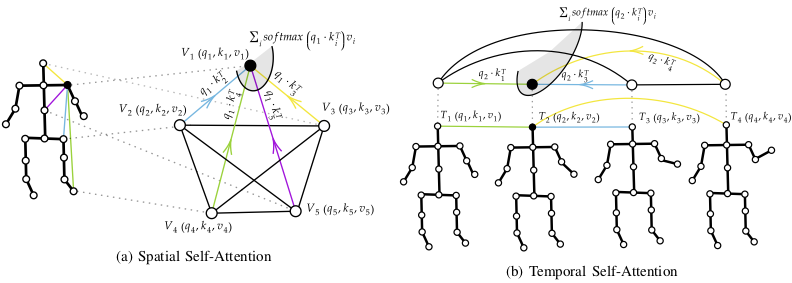
Skeleton-based Human Activity Recognition has achieved great interest in recent years as skeleton data has demonstrated being robust to illumination changes, body scales, dynamic camera views, and complex background. In particular, Spatial-Temporal Graph Convolutional Networks (ST-GCN) demonstrated to be effective in learning both spatial and temporal dependencies on non-Euclidean data such as skeleton graphs. Nevertheless, an effective encoding of the latent information underlying the 3D skeleton is still an open problem, especially when it comes to extracting effective information from joint motion patterns and their correlations. In this work, we propose a novel Spatial-Temporal Transformer network (ST-TR) which models dependencies between joints using the Transformer self-attention operator. In our ST-TR model, a Spatial Self-Attention module (SSA) is used to understand intra-frame interactions between different body parts, and a Temporal Self-Attention module (TSA) to model inter-frame correlations. The two are combined in a two-stream network, whose performance is evaluated on three large-scale datasets, NTU-RGB+D 60, NTU-RGB+D 120, and Kinetics Skeleton 400, consistently improving backbone results. Compared with methods that use the same input data, the proposed ST-TR achieves state-of-the-art performance on all datasets when using joints' coordinates as input, and results on-par with state-of-the-art when adding bones information.
PDF Abstract



 Kinetics
Kinetics
 NTU RGB+D
NTU RGB+D
 NTU RGB+D 120
NTU RGB+D 120

