Spatio-Temporal Inception Graph Convolutional Networks for Skeleton-Based Action Recognition
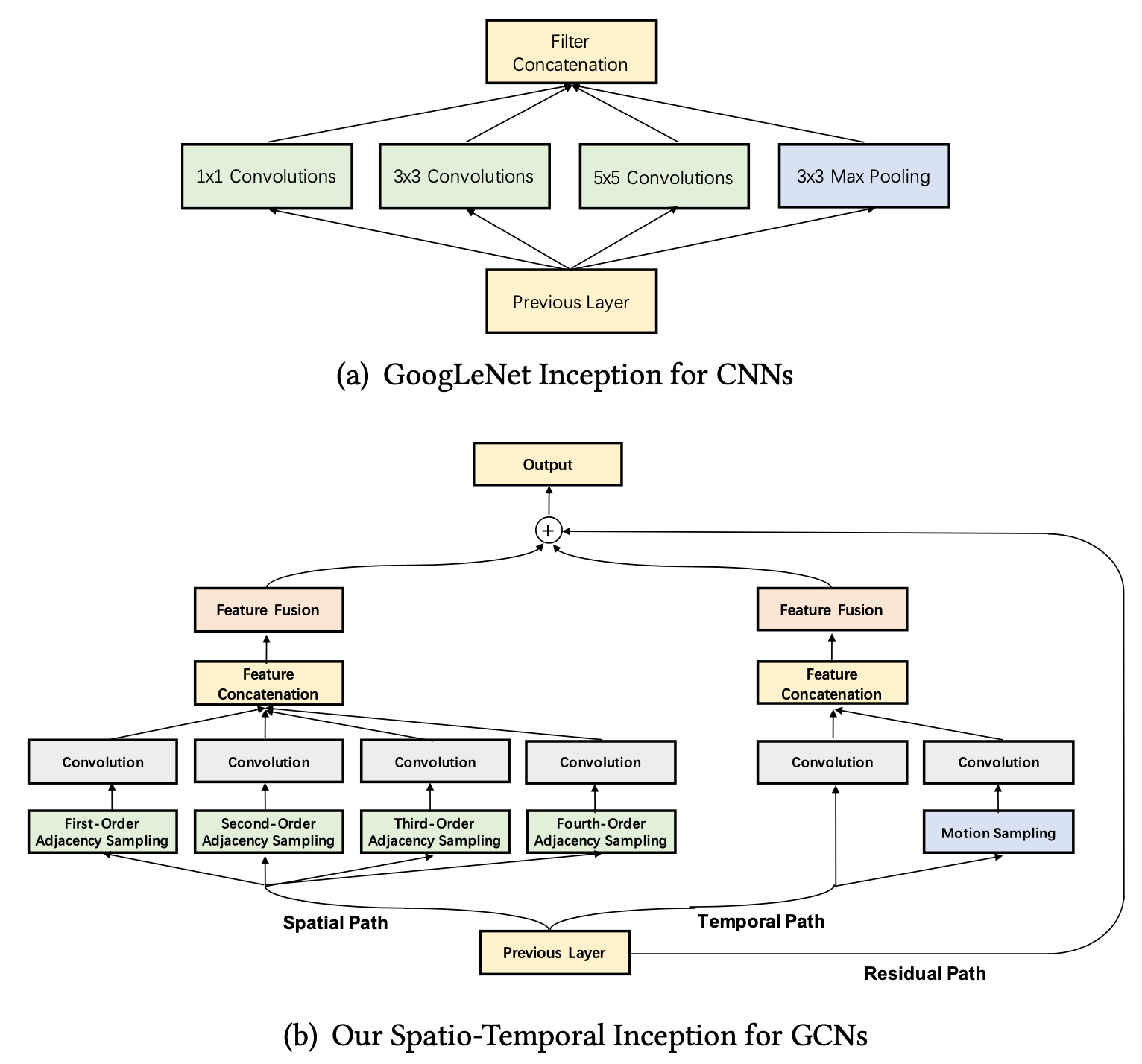
Skeleton-based human action recognition has attracted much attention with the prevalence of accessible depth sensors. Recently, graph convolutional networks (GCNs) have been widely used for this task due to their powerful capability to model graph data. The topology of the adjacency graph is a key factor for modeling the correlations of the input skeletons. Thus, previous methods mainly focus on the design/learning of the graph topology. But once the topology is learned, only a single-scale feature and one transformation exist in each layer of the networks. Many insights, such as multi-scale information and multiple sets of transformations, that have been proven to be very effective in convolutional neural networks (CNNs), have not been investigated in GCNs. The reason is that, due to the gap between graph-structured skeleton data and conventional image/video data, it is very challenging to embed these insights into GCNs. To overcome this gap, we reinvent the split-transform-merge strategy in GCNs for skeleton sequence processing. Specifically, we design a simple and highly modularized graph convolutional network architecture for skeleton-based action recognition. Our network is constructed by repeating a building block that aggregates multi-granularity information from both the spatial and temporal paths. Extensive experiments demonstrate that our network outperforms state-of-the-art methods by a significant margin with only 1/5 of the parameters and 1/10 of the FLOPs. Code is available at https://github.com/yellowtownhz/STIGCN.
PDF Abstract



 Kinetics
Kinetics
 NTU RGB+D
NTU RGB+D
