Speaking Style Conversion in the Waveform Domain Using Discrete Self-Supervised Units
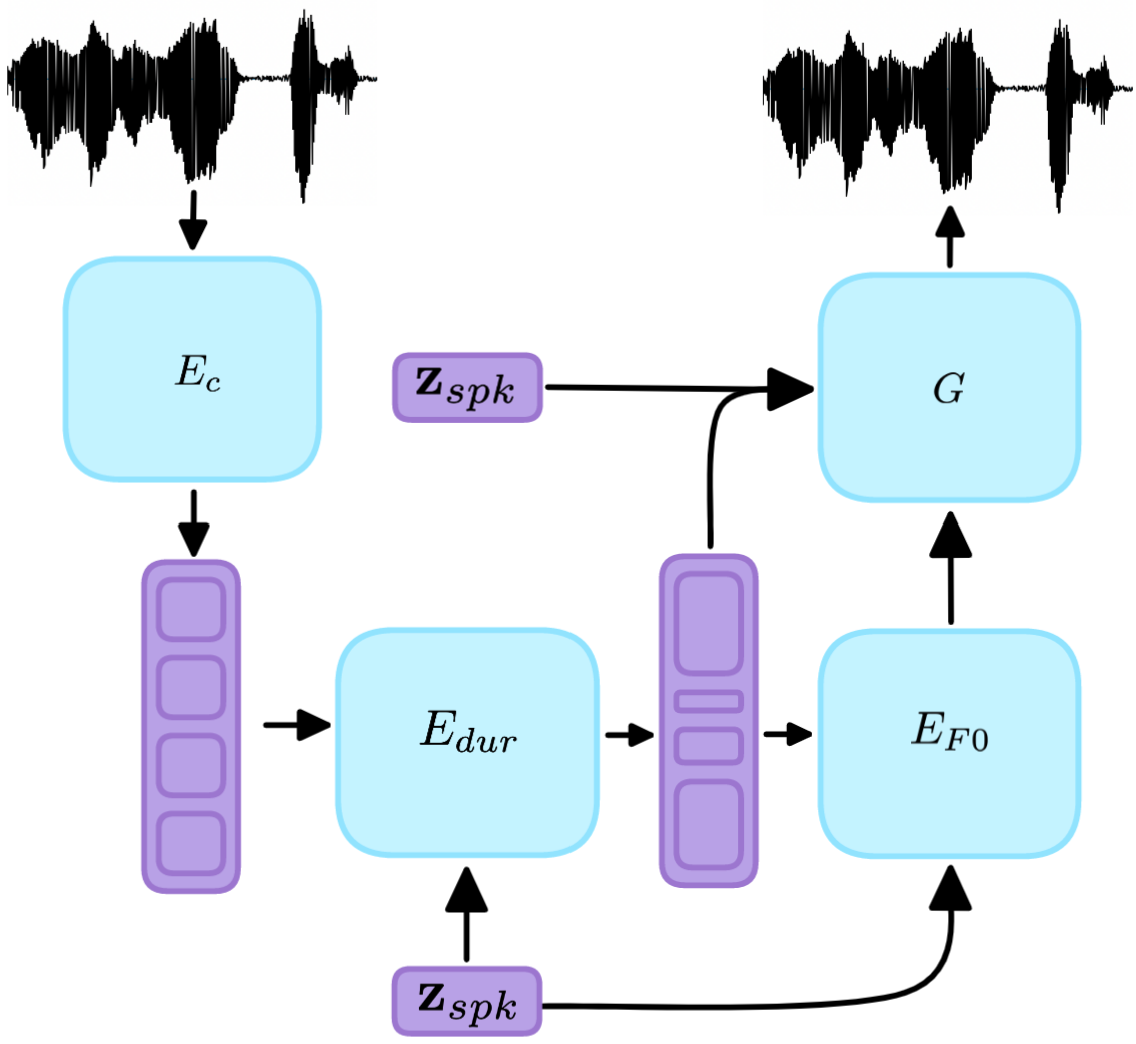
We introduce DISSC, a novel, lightweight method that converts the rhythm, pitch contour and timbre of a recording to a target speaker in a textless manner. Unlike DISSC, most voice conversion (VC) methods focus primarily on timbre, and ignore people's unique speaking style (prosody). The proposed approach uses a pretrained, self-supervised model for encoding speech to discrete units, which makes it simple, effective, and fast to train. All conversion modules are only trained on reconstruction like tasks, thus suitable for any-to-many VC with no paired data. We introduce a suite of quantitative and qualitative evaluation metrics for this setup, and empirically demonstrate that DISSC significantly outperforms the evaluated baselines. Code and samples are available at https://pages.cs.huji.ac.il/adiyoss-lab/dissc/.
PDF Abstract

 ESD
ESD
