SSTVOS: Sparse Spatiotemporal Transformers for Video Object Segmentation
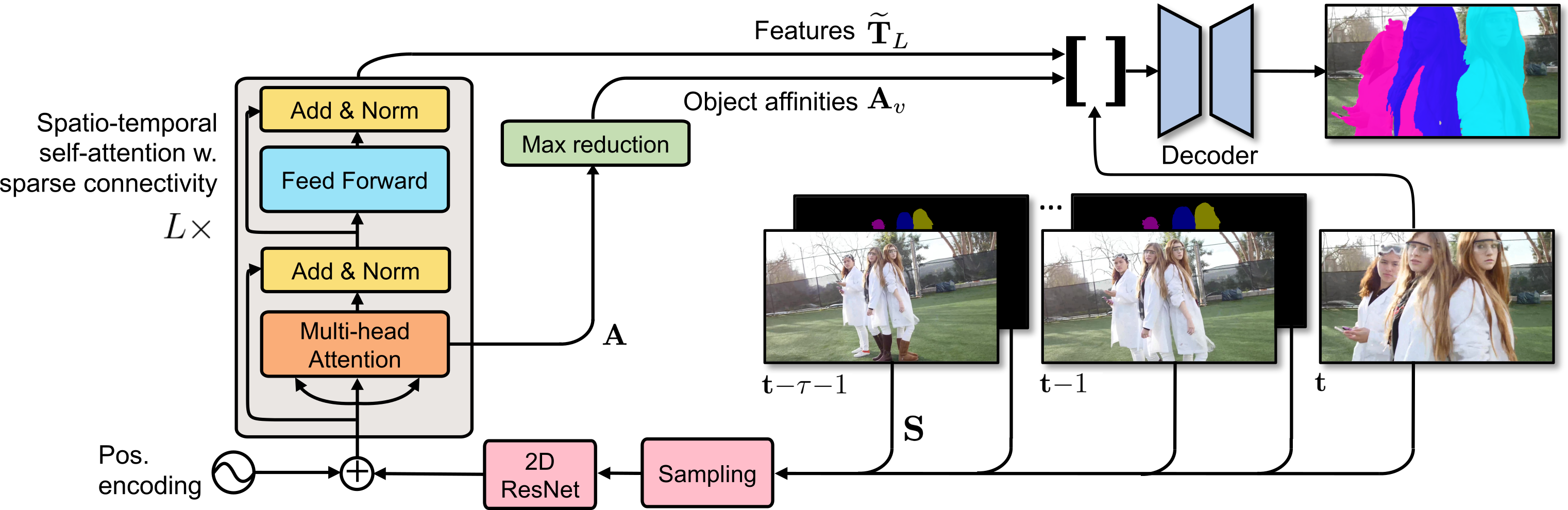
In this paper we introduce a Transformer-based approach to video object segmentation (VOS). To address compounding error and scalability issues of prior work, we propose a scalable, end-to-end method for VOS called Sparse Spatiotemporal Transformers (SST). SST extracts per-pixel representations for each object in a video using sparse attention over spatiotemporal features. Our attention-based formulation for VOS allows a model to learn to attend over a history of multiple frames and provides suitable inductive bias for performing correspondence-like computations necessary for solving motion segmentation. We demonstrate the effectiveness of attention-based over recurrent networks in the spatiotemporal domain. Our method achieves competitive results on YouTube-VOS and DAVIS 2017 with improved scalability and robustness to occlusions compared with the state of the art. Code is available at https://github.com/dukebw/SSTVOS.
PDF Abstract CVPR 2021 PDF CVPR 2021 Abstract




 DAVIS
DAVIS
 DAVIS 2017
DAVIS 2017
 DAVIS 2016
DAVIS 2016
 YouTube-VOS 2018
YouTube-VOS 2018

