Video action detection by learning graph-based spatio-temporal interactions
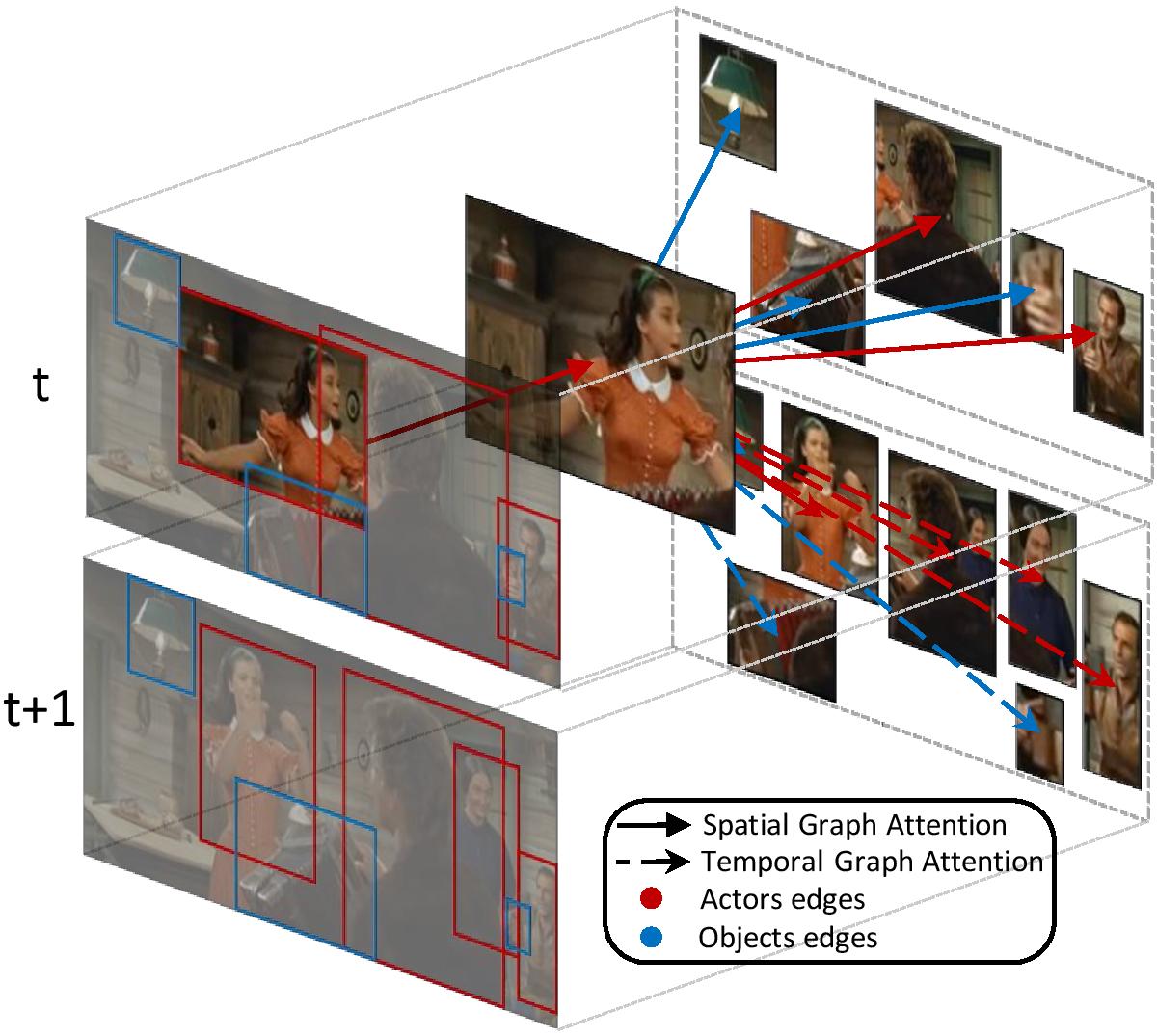
Action Detection is a complex task that aims to detect and classify human actions in video clips. Typically, it has been addressed by processing fine-grained features extracted from a video classification backbone. Recently, thanks to the robustness of object and people detectors, a deeper focus has been added on relationship modelling. Following this line, we propose a graph-based framework to learn high-level interactions between people and objects, in both space and time. In our formulation, spatio-temporal relationships are learned through self-attention on a multi-layer graph structure which can connect entities from consecutive clips, thus considering long-range spatial and temporal dependencies. The proposed module is backbone independent by design and does not require end-to-end training. Extensive experiments are conducted on the AVA dataset, where our model demonstrates state-of-the-art results and consistent improvements over baselines built with different backbones. Code is publicly available at https://github.com/aimagelab/STAGE_action_detection.
PDF Abstract



 ImageNet
ImageNet
 MS COCO
MS COCO
 Kinetics
Kinetics
 Kinetics 400
Kinetics 400
