Data Efficient Stagewise Knowledge Distillation
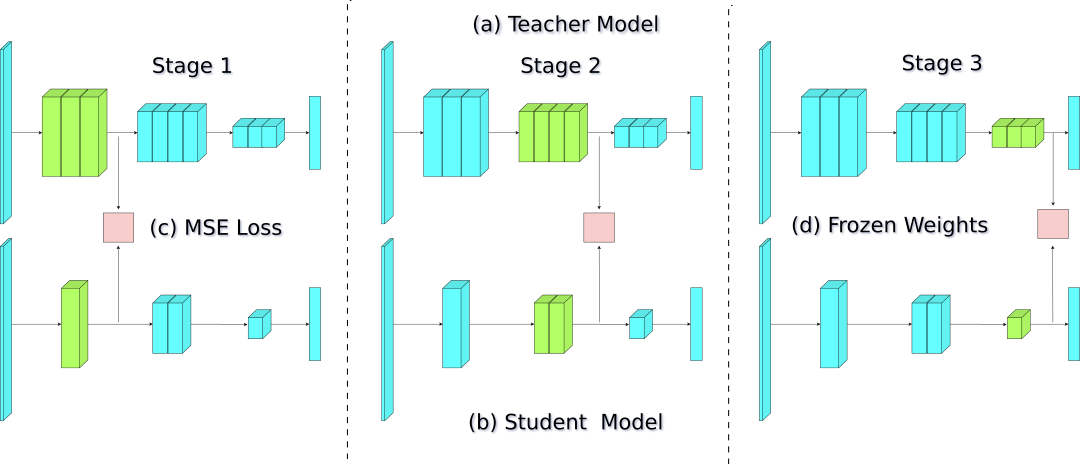
Despite the success of Deep Learning (DL), the deployment of modern DL models requiring large computational power poses a significant problem for resource-constrained systems. This necessitates building compact networks that reduce computations while preserving performance. Traditional Knowledge Distillation (KD) methods that transfer knowledge from teacher to student (a) use a single-stage and (b) require the whole data set while distilling the knowledge to the student. In this work, we propose a new method called Stagewise Knowledge Distillation (SKD) which builds on traditional KD methods by progressive stagewise training to leverage the knowledge gained from the teacher, resulting in data-efficient distillation process. We evaluate our method on classification and semantic segmentation tasks. We show, across the tested tasks, significant performance gains even with a fraction of the data used in distillation, without compromising on the metric. We also compare our method with existing KD techniques and show that SKD outperforms them. Moreover, our method can be viewed as a generalized model compression technique that complements other model compression methods such as quantization or pruning.
PDF Abstract


 CIFAR-10
CIFAR-10
 Imagenette
Imagenette
 Imagewoof
Imagewoof
