Staleness-aware Async-SGD for Distributed Deep Learning
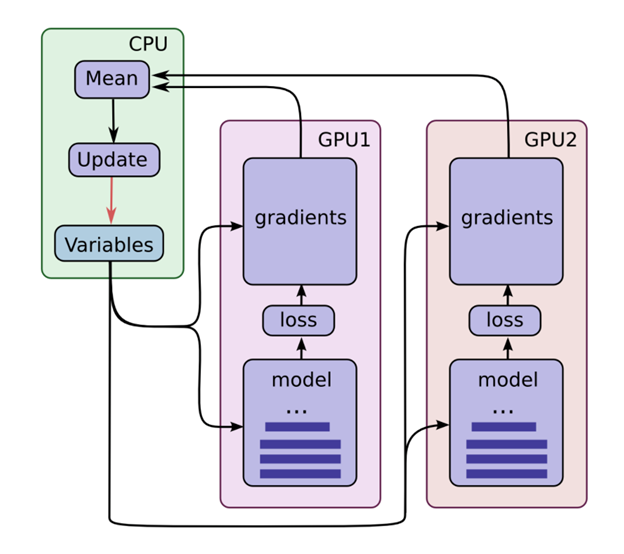
Deep neural networks have been shown to achieve state-of-the-art performance in several machine learning tasks. Stochastic Gradient Descent (SGD) is the preferred optimization algorithm for training these networks and asynchronous SGD (ASGD) has been widely adopted for accelerating the training of large-scale deep networks in a distributed computing environment. However, in practice it is quite challenging to tune the training hyperparameters (such as learning rate) when using ASGD so as achieve convergence and linear speedup, since the stability of the optimization algorithm is strongly influenced by the asynchronous nature of parameter updates. In this paper, we propose a variant of the ASGD algorithm in which the learning rate is modulated according to the gradient staleness and provide theoretical guarantees for convergence of this algorithm. Experimental verification is performed on commonly-used image classification benchmarks: CIFAR10 and Imagenet to demonstrate the superior effectiveness of the proposed approach, compared to SSGD (Synchronous SGD) and the conventional ASGD algorithm.
PDF Abstract


 CIFAR-10
CIFAR-10
