StarGAN-VC: Non-parallel many-to-many voice conversion with star generative adversarial networks
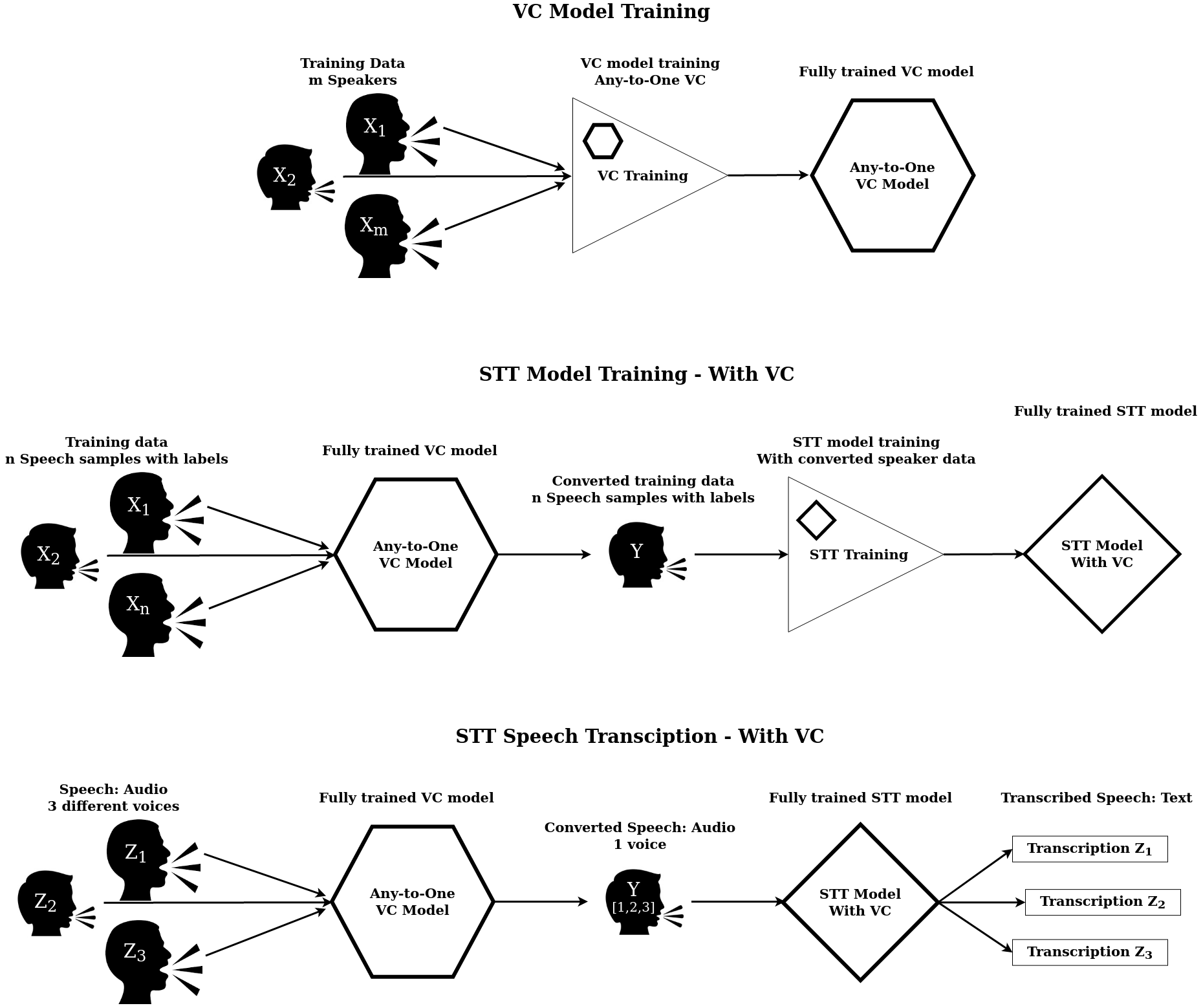
This paper proposes a method that allows non-parallel many-to-many voice conversion (VC) by using a variant of a generative adversarial network (GAN) called StarGAN. Our method, which we call StarGAN-VC, is noteworthy in that it (1) requires no parallel utterances, transcriptions, or time alignment procedures for speech generator training, (2) simultaneously learns many-to-many mappings across different attribute domains using a single generator network, (3) is able to generate converted speech signals quickly enough to allow real-time implementations and (4) requires only several minutes of training examples to generate reasonably realistic-sounding speech. Subjective evaluation experiments on a non-parallel many-to-many speaker identity conversion task revealed that the proposed method obtained higher sound quality and speaker similarity than a state-of-the-art method based on variational autoencoding GANs.
PDF Abstract


