StarGAN-VC2: Rethinking Conditional Methods for StarGAN-Based Voice Conversion
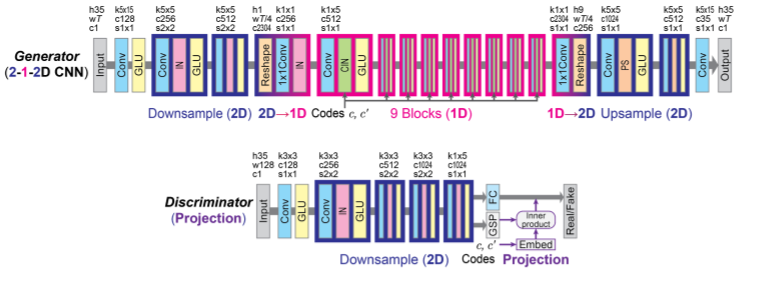
Non-parallel multi-domain voice conversion (VC) is a technique for learning mappings among multiple domains without relying on parallel data. This is important but challenging owing to the requirement of learning multiple mappings and the non-availability of explicit supervision. Recently, StarGAN-VC has garnered attention owing to its ability to solve this problem only using a single generator. However, there is still a gap between real and converted speech. To bridge this gap, we rethink conditional methods of StarGAN-VC, which are key components for achieving non-parallel multi-domain VC in a single model, and propose an improved variant called StarGAN-VC2. Particularly, we rethink conditional methods in two aspects: training objectives and network architectures. For the former, we propose a source-and-target conditional adversarial loss that allows all source domain data to be convertible to the target domain data. For the latter, we introduce a modulation-based conditional method that can transform the modulation of the acoustic feature in a domain-specific manner. We evaluated our methods on non-parallel multi-speaker VC. An objective evaluation demonstrates that our proposed methods improve speech quality in terms of both global and local structure measures. Furthermore, a subjective evaluation shows that StarGAN-VC2 outperforms StarGAN-VC in terms of naturalness and speaker similarity. The converted speech samples are provided at http://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/stargan-vc2/index.html.
PDF Abstract


