FrostNet: Towards Quantization-Aware Network Architecture Search
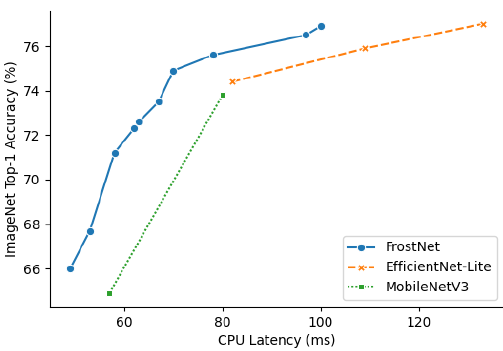
INT8 quantization has become one of the standard techniques for deploying convolutional neural networks (CNNs) on edge devices to reduce the memory and computational resource usages. By analyzing quantized performances of existing mobile-target network architectures, we can raise an issue regarding the importance of network architecture for optimal INT8 quantization. In this paper, we present a new network architecture search (NAS) procedure to find a network that guarantees both full-precision (FLOAT32) and quantized (INT8) performances. We first propose critical but straightforward optimization method which enables quantization-aware training (QAT) : floating-point statistic assisting (StatAssist) and stochastic gradient boosting (GradBoost). By integrating the gradient-based NAS with StatAssist and GradBoost, we discovered a quantization-efficient network building block, Frost bottleneck. Furthermore, we used Frost bottleneck as the building block for hardware-aware NAS to obtain quantization-efficient networks, FrostNets, which show improved quantization performances compared to other mobile-target networks while maintaining competitive FLOAT32 performance. Our FrostNets achieve higher recognition accuracy than existing CNNs with comparable latency when quantized, due to higher latency reduction rate (average 65%).
PDF Abstract



 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 MS COCO
MS COCO
