Storywrangler: A massive exploratorium for sociolinguistic, cultural, socioeconomic, and political timelines using Twitter
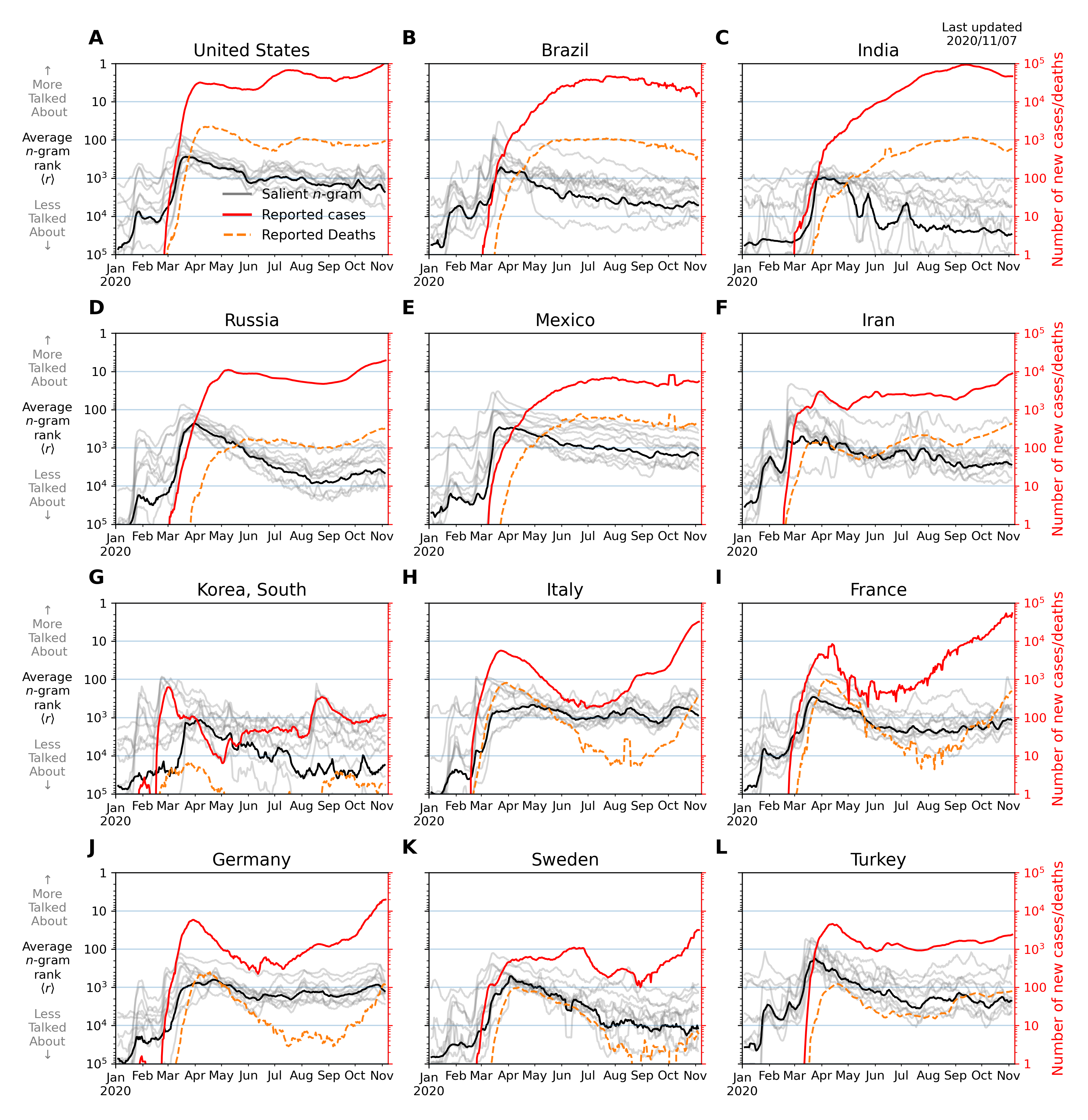
In real-time, social media data strongly imprints world events, popular culture, and day-to-day conversations by millions of ordinary people at a scale that is scarcely conventionalized and recorded. Vitally, and absent from many standard corpora such as books and news archives, sharing and commenting mechanisms are native to social media platforms, enabling us to quantify social amplification (i.e., popularity) of trending storylines and contemporary cultural phenomena. Here, we describe Storywrangler, a natural language processing instrument designed to carry out an ongoing, day-scale curation of over 100 billion tweets containing roughly 1 trillion 1-grams from 2008 to 2021. For each day, we break tweets into unigrams, bigrams, and trigrams spanning over 100 languages. We track n-gram usage frequencies, and generate Zipf distributions, for words, hashtags, handles, numerals, symbols, and emojis. We make the data set available through an interactive time series viewer, and as downloadable time series and daily distributions. Although Storywrangler leverages Twitter data, our method of extracting and tracking dynamic changes of n-grams can be extended to any similar social media platform. We showcase a few examples of the many possible avenues of study we aim to enable including how social amplification can be visualized through 'contagiograms'. We also present some example case studies that bridge n-gram time series with disparate data sources to explore sociotechnical dynamics of famous individuals, box office success, and social unrest.
PDF Abstract

 MovieLens
MovieLens
 Cable TV News
Cable TV News
