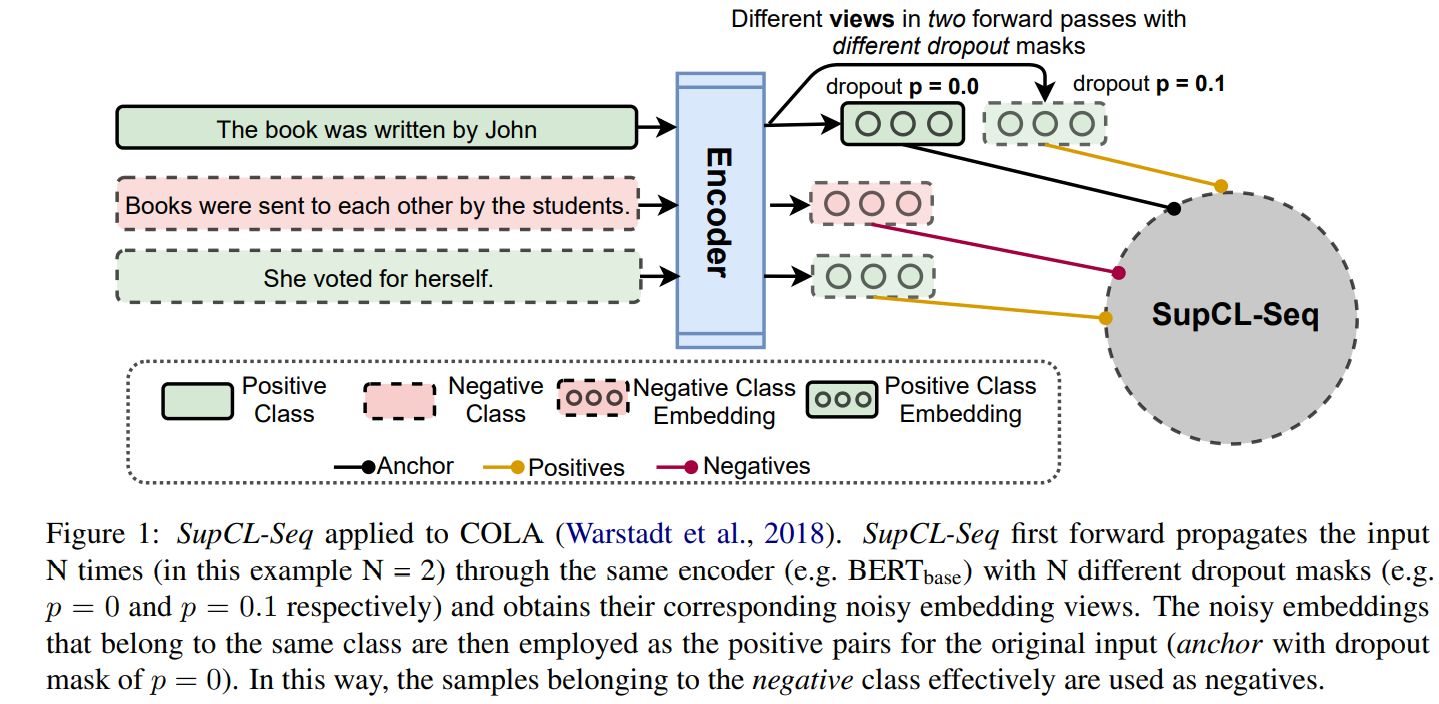
SupCL-Seq: Supervised Contrastive Learning for Downstream Optimized Sequence Representations
While contrastive learning is proven to be an effective training strategy in computer vision, Natural Language Processing (NLP) is only recently adopting it as a self-supervised alternative to Masked Language Modeling (MLM) for improving sequence representations. This paper introduces SupCL-Seq, which extends the supervised contrastive learning from computer vision to the optimization of sequence representations in NLP. By altering the dropout mask probability in standard Transformer architectures, for every representation (anchor), we generate augmented altered views. A supervised contrastive loss is then utilized to maximize the system's capability of pulling together similar samples (e.g., anchors and their altered views) and pushing apart the samples belonging to the other classes. Despite its simplicity, SupCLSeq leads to large gains in many sequence classification tasks on the GLUE benchmark compared to a standard BERTbase, including 6% absolute improvement on CoLA, 5.4% on MRPC, 4.7% on RTE and 2.6% on STSB. We also show consistent gains over self supervised contrastively learned representations, especially in non-semantic tasks. Finally we show that these gains are not solely due to augmentation, but rather to a downstream optimized sequence representation. Code: https://github.com/hooman650/SupCL-Seq
PDF Abstract Findings (EMNLP) 2021 PDF Findings (EMNLP) 2021 Abstract



 GLUE
GLUE
 CoLA
CoLA
