Surgical Instruction Generation with Transformers
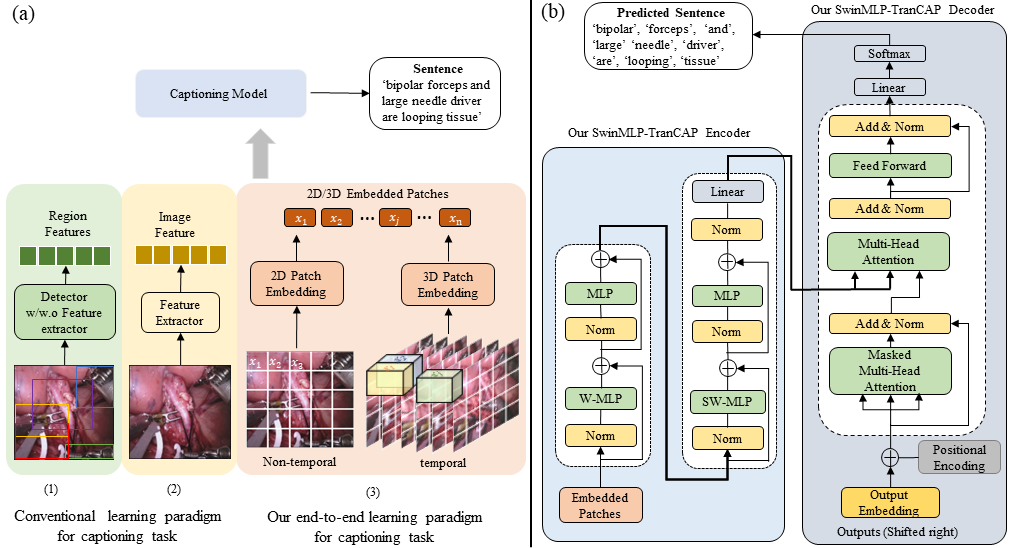
Automatic surgical instruction generation is a prerequisite towards intra-operative context-aware surgical assistance. However, generating instructions from surgical scenes is challenging, as it requires jointly understanding the surgical activity of current view and modelling relationships between visual information and textual description. Inspired by the neural machine translation and imaging captioning tasks in open domain, we introduce a transformer-backboned encoder-decoder network with self-critical reinforcement learning to generate instructions from surgical images. We evaluate the effectiveness of our method on DAISI dataset, which includes 290 procedures from various medical disciplines. Our approach outperforms the existing baseline over all caption evaluation metrics. The results demonstrate the benefits of the encoder-decoder structure backboned by transformer in handling multimodal context.
PDF Abstract


 MS COCO
MS COCO
