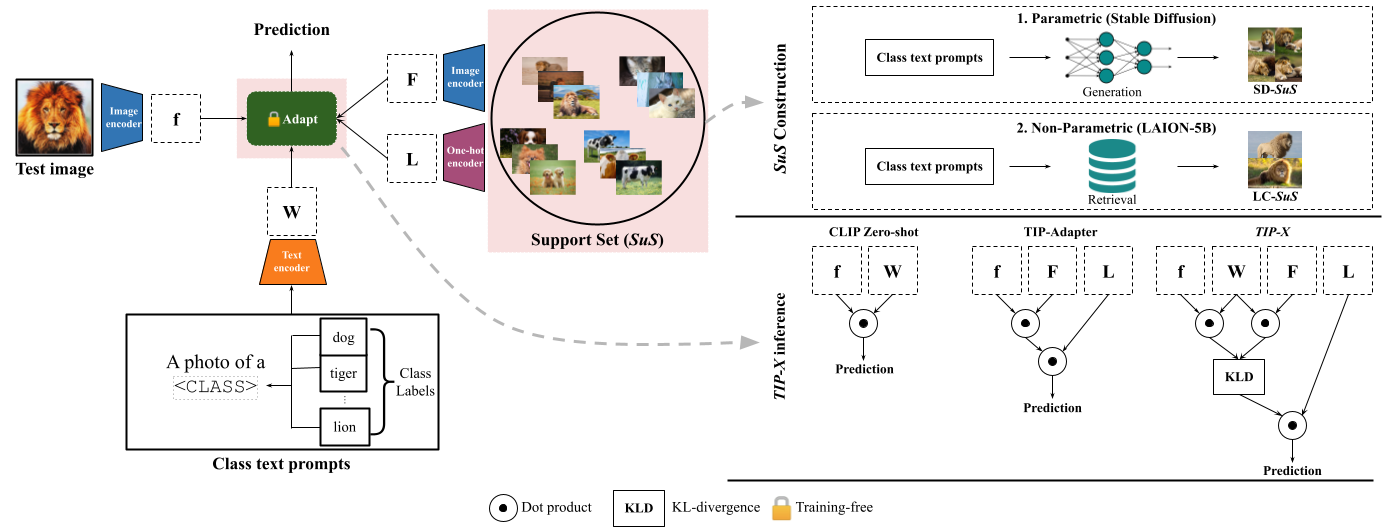
SuS-X: Training-Free Name-Only Transfer of Vision-Language Models
Contrastive Language-Image Pre-training (CLIP) has emerged as a simple yet effective way to train large-scale vision-language models. CLIP demonstrates impressive zero-shot classification and retrieval on diverse downstream tasks. However, to leverage its full potential, fine-tuning still appears to be necessary. Fine-tuning the entire CLIP model can be resource-intensive and unstable. Moreover, recent methods that aim to circumvent this need for fine-tuning still require access to images from the target distribution. In this paper, we pursue a different approach and explore the regime of training-free "name-only transfer" in which the only knowledge we possess about the downstream task comprises the names of downstream target categories. We propose a novel method, SuS-X, consisting of two key building blocks -- SuS and TIP-X, that requires neither intensive fine-tuning nor costly labelled data. SuS-X achieves state-of-the-art zero-shot classification results on 19 benchmark datasets. We further show the utility of TIP-X in the training-free few-shot setting, where we again achieve state-of-the-art results over strong training-free baselines. Code is available at https://github.com/vishaal27/SuS-X.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract


 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 CUB-200-2011
CUB-200-2011
 UCF101
UCF101
 Oxford 102 Flower
Oxford 102 Flower
 Stanford Cars
Stanford Cars
 DTD
DTD
 Food-101
Food-101
 Caltech-101
Caltech-101
 EuroSAT
EuroSAT
 FGVC-Aircraft
FGVC-Aircraft
 Caltech-256
Caltech-256
 ImageNet-R
ImageNet-R
 ImageNet-Sketch
ImageNet-Sketch
 LAION-5B
LAION-5B
 Birdsnap
Birdsnap
