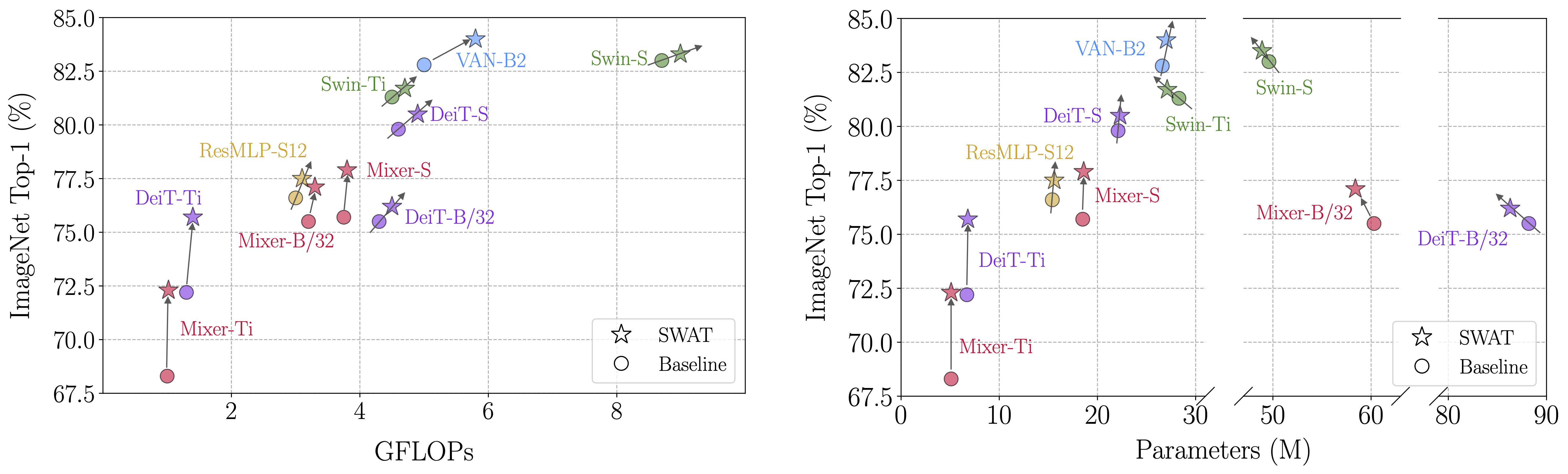
SWAT: Spatial Structure Within and Among Tokens
Modeling visual data as tokens (i.e., image patches) using attention mechanisms, feed-forward networks or convolutions has been highly effective in recent years. Such methods usually have a common pipeline: a tokenization method, followed by a set of layers/blocks for information mixing, both within and among tokens. When image patches are converted into tokens, they are often flattened, discarding the spatial structure within each patch. As a result, any processing that follows (eg: multi-head self-attention) may fail to recover and/or benefit from such information. In this paper, we argue that models can have significant gains when spatial structure is preserved during tokenization, and is explicitly used during the mixing stage. We propose two key contributions: (1) Structure-aware Tokenization and, (2) Structure-aware Mixing, both of which can be combined with existing models with minimal effort. We introduce a family of models (SWAT), showing improvements over the likes of DeiT, MLP-Mixer and Swin Transformer, across multiple benchmarks including ImageNet classification and ADE20K segmentation. Our code is available at https://github.com/kkahatapitiya/SWAT.
PDF Abstract
 ImageNet
ImageNet
