
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
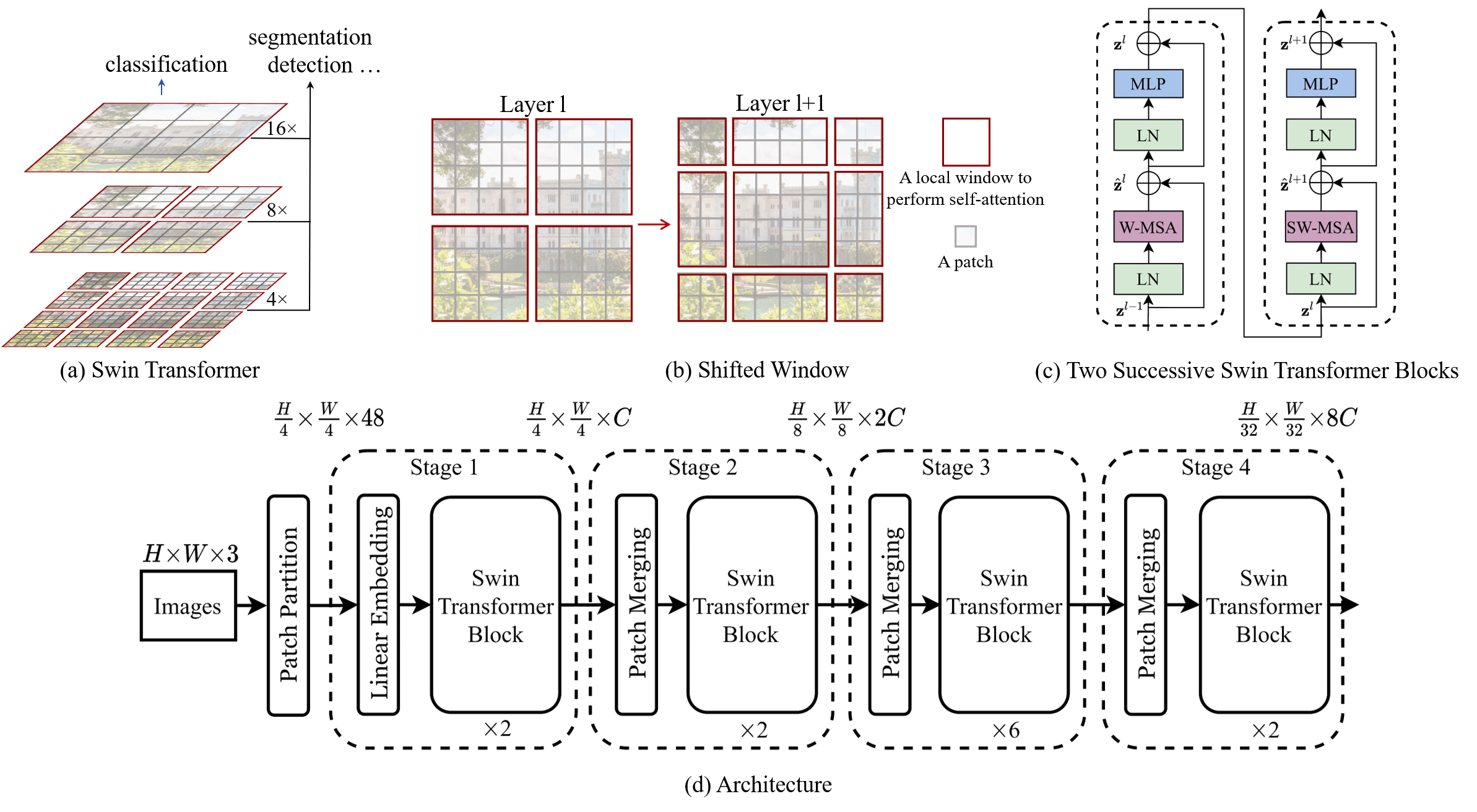
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text. To address these differences, we propose a hierarchical Transformer whose representation is computed with \textbf{S}hifted \textbf{win}dows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation (53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones. The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures. The code and models are publicly available at~\url{https://github.com/microsoft/Swin-Transformer}.
PDF Abstract ICCV 2021 PDF ICCV 2021 Abstract Spaces
Spaces





 Colab
Colab






 ImageNet
ImageNet
 MS COCO
MS COCO
 ADE20K
ADE20K
 OmniBenchmark
OmniBenchmark
 FoodSeg103
FoodSeg103
 Separated COCO
Separated COCO
 Occluded COCO
Occluded COCO

