Synthesizer: Rethinking Self-Attention in Transformer Models
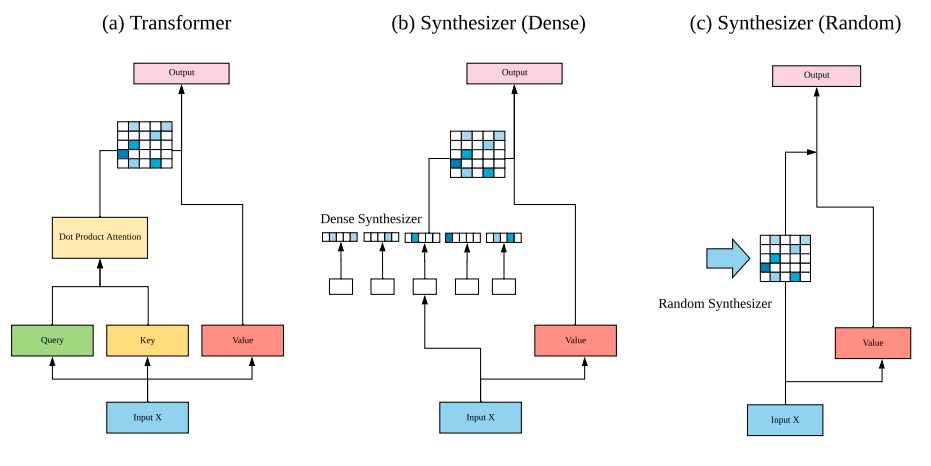
The dot product self-attention is known to be central and indispensable to state-of-the-art Transformer models. But is it really required? This paper investigates the true importance and contribution of the dot product-based self-attention mechanism on the performance of Transformer models. Via extensive experiments, we find that (1) random alignment matrices surprisingly perform quite competitively and (2) learning attention weights from token-token (query-key) interactions is useful but not that important after all. To this end, we propose \textsc{Synthesizer}, a model that learns synthetic attention weights without token-token interactions. In our experiments, we first show that simple Synthesizers achieve highly competitive performance when compared against vanilla Transformer models across a range of tasks, including machine translation, language modeling, text generation and GLUE/SuperGLUE benchmarks. When composed with dot product attention, we find that Synthesizers consistently outperform Transformers. Moreover, we conduct additional comparisons of Synthesizers against Dynamic Convolutions, showing that simple Random Synthesizer is not only $60\%$ faster but also improves perplexity by a relative $3.5\%$. Finally, we show that simple factorized Synthesizers can outperform Linformers on encoding only tasks.
PDF AbstractCode









Datasets
 MRPC
MRPC
 C4
C4
 CoLA
CoLA
 CNN/Daily Mail
CNN/Daily Mail
 WMT 2014
WMT 2014
 PERSONA-CHAT
PERSONA-CHAT
Results from the Paper
 Ranked #1 on
Dialogue Generation
on Persona-Chat
(BLEU-1 metric, using extra
training data)
Ranked #1 on
Dialogue Generation
on Persona-Chat
(BLEU-1 metric, using extra
training data)
