TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning
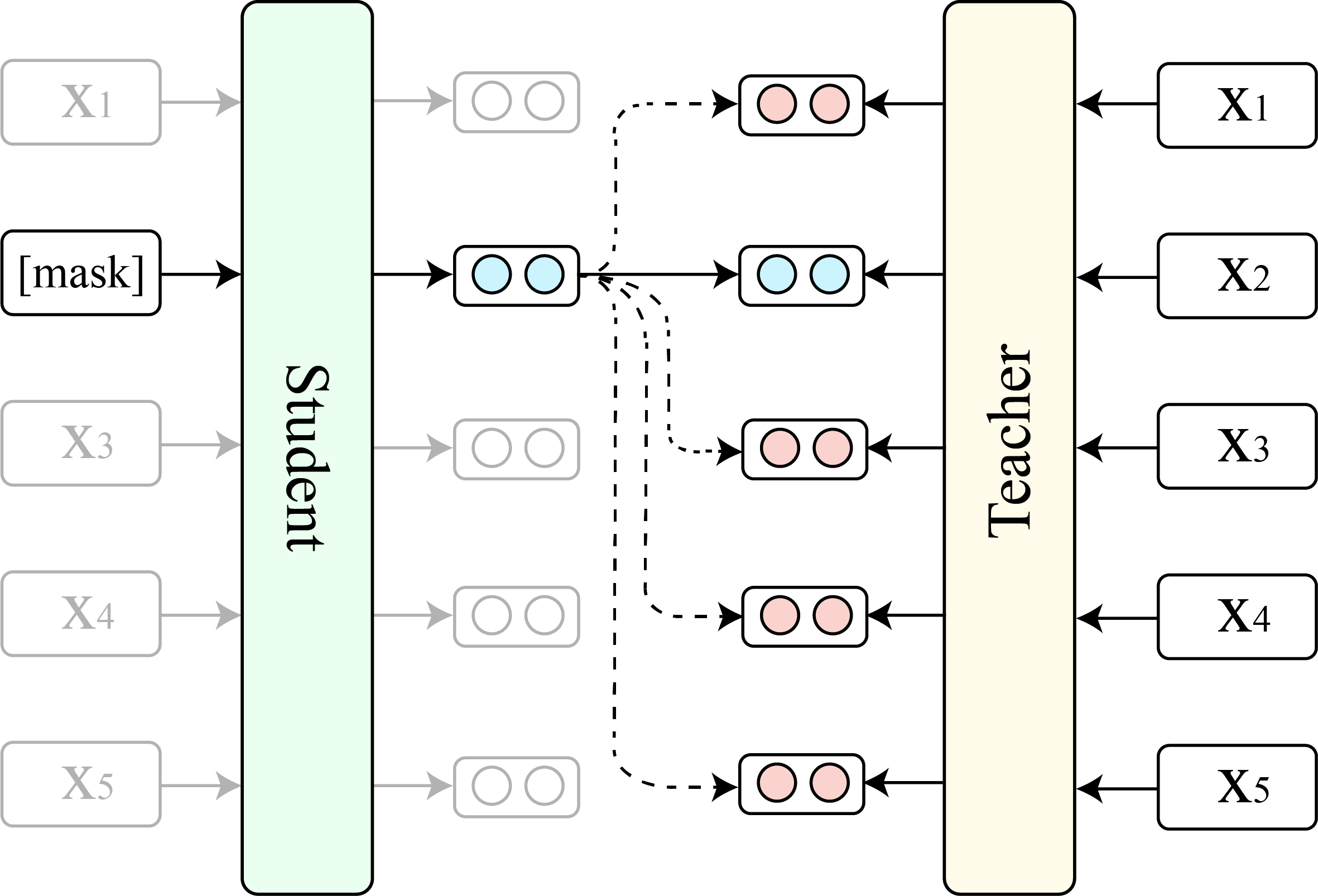
Masked language models (MLMs) such as BERT and RoBERTa have revolutionized the field of Natural Language Understanding in the past few years. However, existing pre-trained MLMs often output an anisotropic distribution of token representations that occupies a narrow subset of the entire representation space. Such token representations are not ideal, especially for tasks that demand discriminative semantic meanings of distinct tokens. In this work, we propose TaCL (Token-aware Contrastive Learning), a novel continual pre-training approach that encourages BERT to learn an isotropic and discriminative distribution of token representations. TaCL is fully unsupervised and requires no additional data. We extensively test our approach on a wide range of English and Chinese benchmarks. The results show that TaCL brings consistent and notable improvements over the original BERT model. Furthermore, we conduct detailed analysis to reveal the merits and inner-workings of our approach.
PDF Abstract Findings (NAACL) 2022 PDF Findings (NAACL) 2022 Abstract


 GLUE
GLUE
 QNLI
QNLI
