Temporal Memory Attention for Video Semantic Segmentation
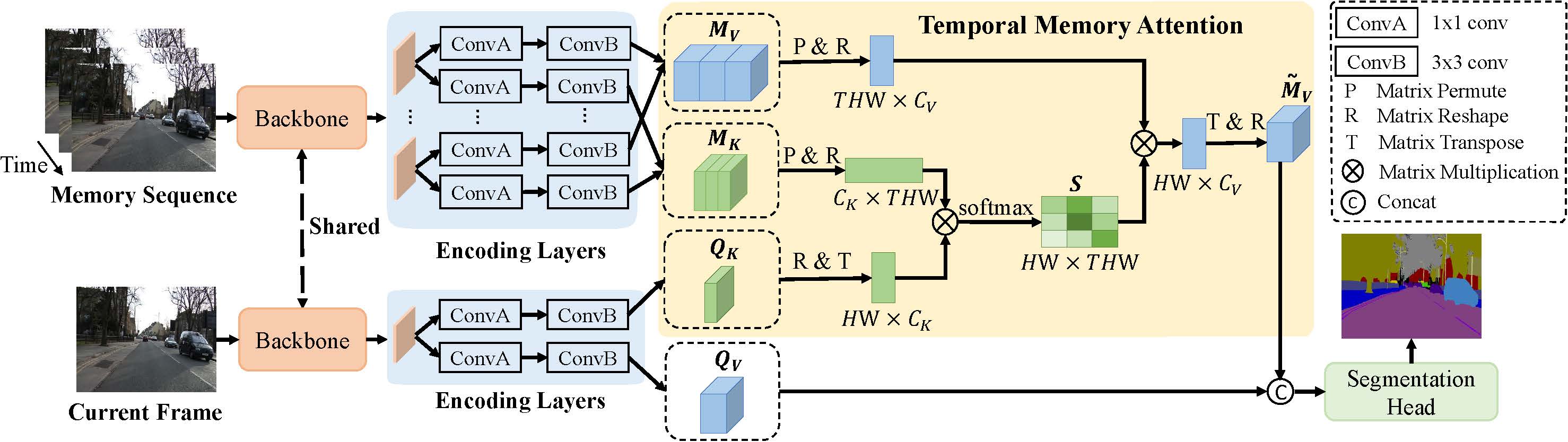
Video semantic segmentation requires to utilize the complex temporal relations between frames of the video sequence. Previous works usually exploit accurate optical flow to leverage the temporal relations, which suffer much from heavy computational cost. In this paper, we propose a Temporal Memory Attention Network (TMANet) to adaptively integrate the long-range temporal relations over the video sequence based on the self-attention mechanism without exhaustive optical flow prediction. Specially, we construct a memory using several past frames to store the temporal information of the current frame. We then propose a temporal memory attention module to capture the relation between the current frame and the memory to enhance the representation of the current frame. Our method achieves new state-of-the-art performances on two challenging video semantic segmentation datasets, particularly 80.3% mIoU on Cityscapes and 76.5% mIoU on CamVid with ResNet-50.
PDF Abstract


 Cityscapes
Cityscapes
 CamVid
CamVid

