Texts as Images in Prompt Tuning for Multi-Label Image Recognition
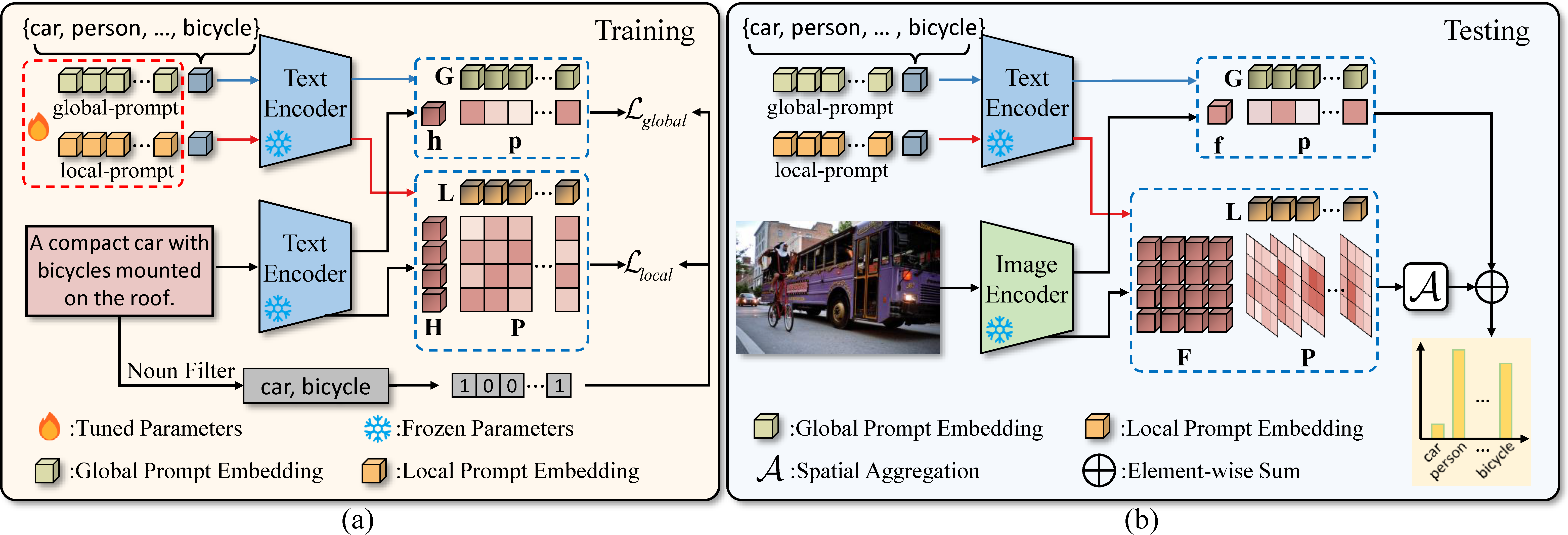
Prompt tuning has been employed as an efficient way to adapt large vision-language pre-trained models (e.g. CLIP) to various downstream tasks in data-limited or label-limited settings. Nonetheless, visual data (e.g., images) is by default prerequisite for learning prompts in existing methods. In this work, we advocate that the effectiveness of image-text contrastive learning in aligning the two modalities (for training CLIP) further makes it feasible to treat texts as images for prompt tuning and introduce TaI prompting. In contrast to the visual data, text descriptions are easy to collect, and their class labels can be directly derived. Particularly, we apply TaI prompting to multi-label image recognition, where sentences in the wild serve as alternatives to images for prompt tuning. Moreover, with TaI, double-grained prompt tuning (TaI-DPT) is further presented to extract both coarse-grained and fine-grained embeddings for enhancing the multi-label recognition performance. Experimental results show that our proposed TaI-DPT outperforms zero-shot CLIP by a large margin on multiple benchmarks, e.g., MS-COCO, VOC2007, and NUS-WIDE, while it can be combined with existing methods of prompting from images to improve recognition performance further. Code is released at https://github.com/guozix/TaI-DPT.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract


 MS COCO
MS COCO
 NUS-WIDE
NUS-WIDE
 PASCAL VOC 2007
PASCAL VOC 2007

