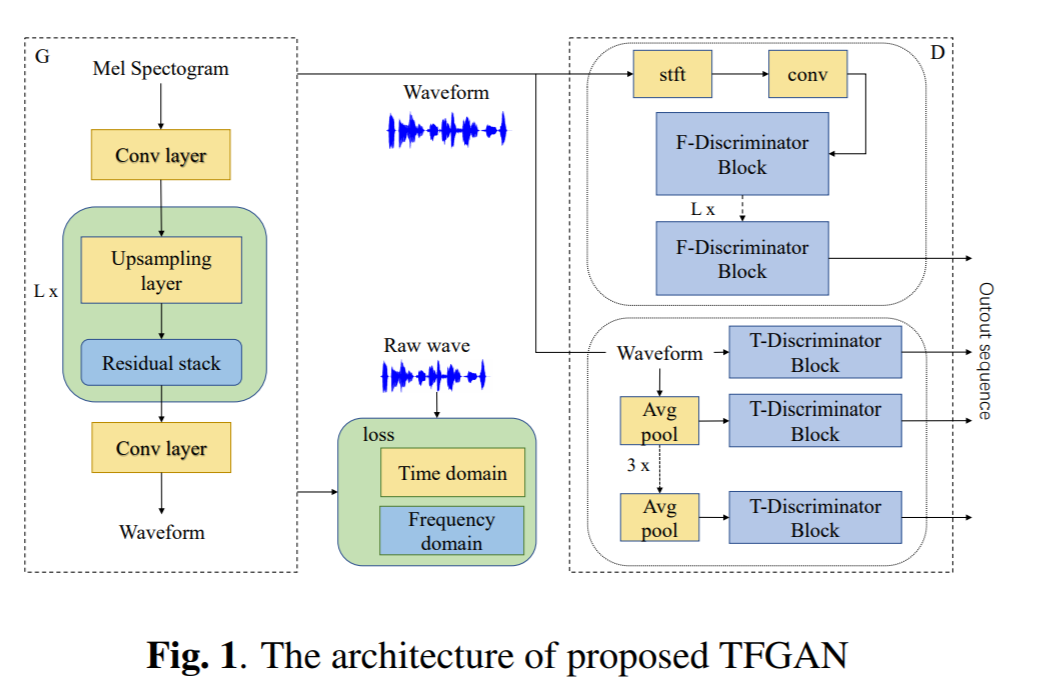
TFGAN: Time and Frequency Domain Based Generative Adversarial Network for High-fidelity Speech Synthesis
Recently, GAN based speech synthesis methods, such as MelGAN, have become very popular. Compared to conventional autoregressive based methods, parallel structures based generators make waveform generation process fast and stable. However, the quality of generated speech by autoregressive based neural vocoders, such as WaveRNN, is still higher than GAN. To address this issue, we propose a novel vocoder model: TFGAN, which is adversarially learned both in time and frequency domain. On one hand, we propose to discriminate ground-truth waveform from synthetic one in frequency domain for offering more consistency guarantees instead of only in time domain. On the other hand, in contrast to the conventionally frequency-domain STFT loss approach or feature map loss by discriminator to learn waveform, we propose a set of time-domain loss that encourage the generator to capture the waveform directly. TFGAN has nearly same synthesis speed as MelGAN, but the fidelity is significantly improved by our novel learning method. In our experiments, TFGAN shows the ability to achieve comparable mean opinion score (MOS) than autoregressive vocoder under speech synthesis context.
PDF Abstract


