Tha3aroon at NSURL-2019 Task 8: Semantic Question Similarity in Arabic
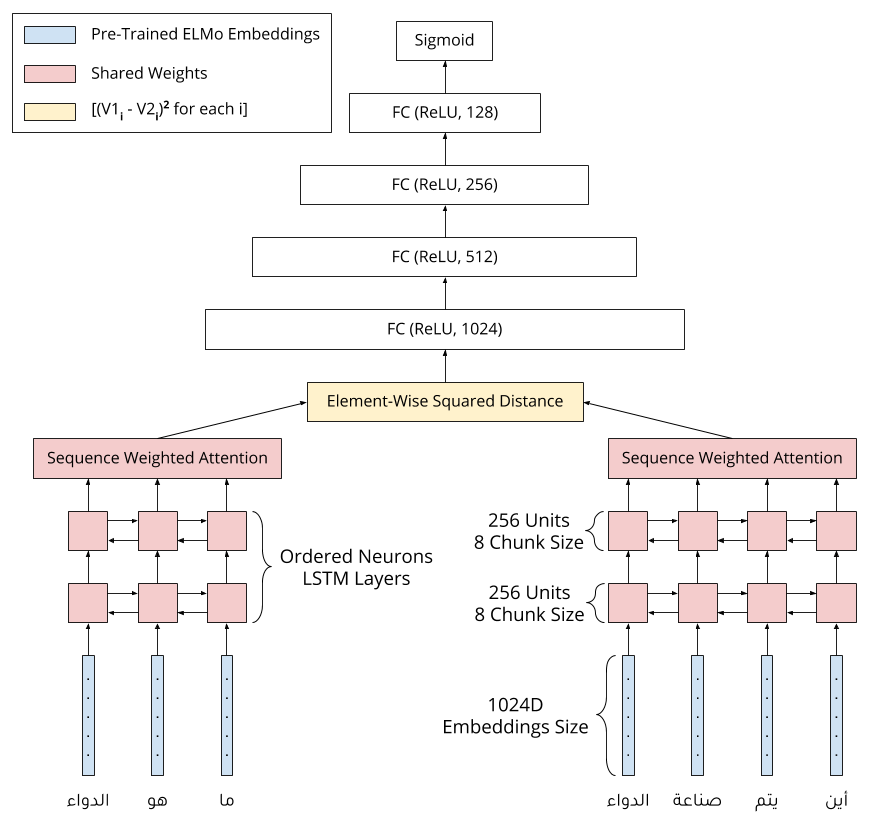
In this paper, we describe our team's effort on the semantic text question similarity task of NSURL 2019. Our top performing system utilizes several innovative data augmentation techniques to enlarge the training data. Then, it takes ELMo pre-trained contextual embeddings of the data and feeds them into an ON-LSTM network with self-attention. This results in sequence representation vectors that are used to predict the relation between the question pairs. The model is ranked in the 1st place with 96.499 F1-score (same as the second place F1-score) and the 2nd place with 94.848 F1-score (differs by 1.076 F1-score from the first place) on the public and private leaderboards, respectively.
PDF Abstract NSURL 2019 PDF NSURL 2019 Abstract

Datasets
Add Datasets
introduced or used in this paper

