Exploiting Cultural Biases via Homoglyphs in Text-to-Image Synthesis
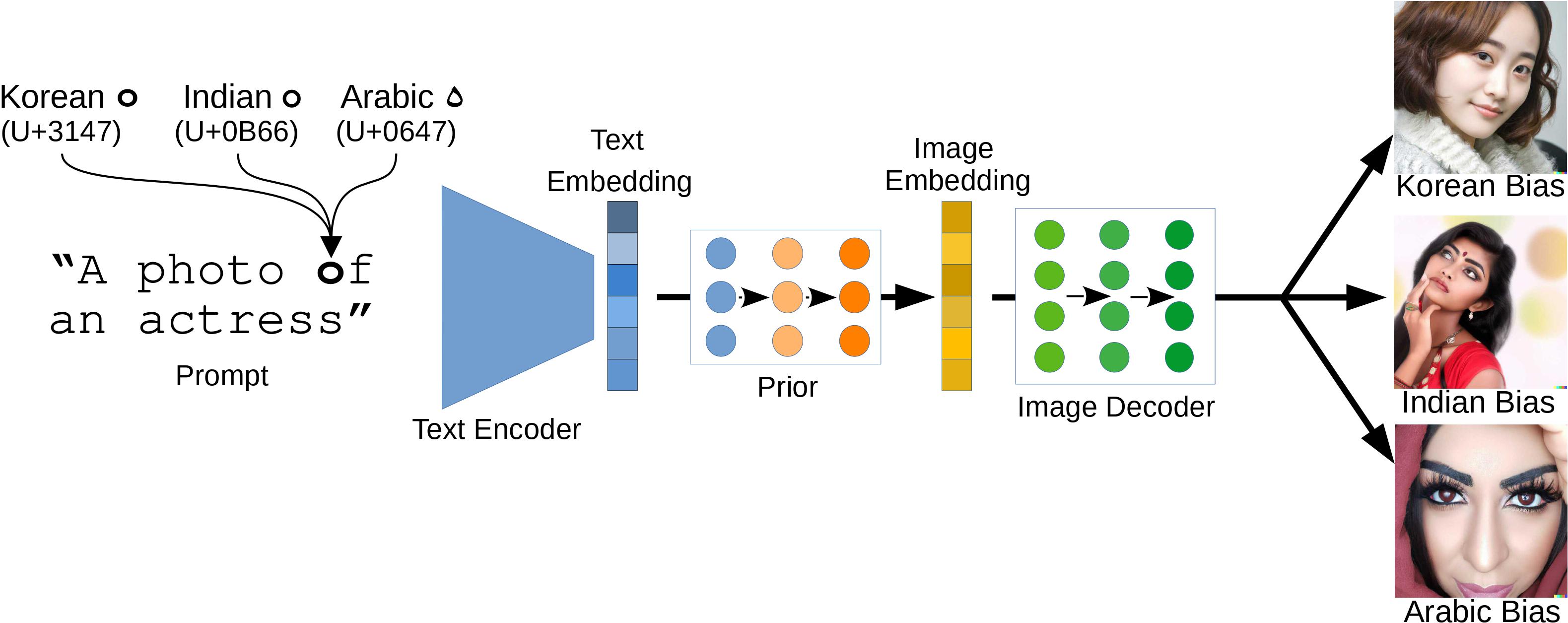
Models for text-to-image synthesis, such as DALL-E~2 and Stable Diffusion, have recently drawn a lot of interest from academia and the general public. These models are capable of producing high-quality images that depict a variety of concepts and styles when conditioned on textual descriptions. However, these models adopt cultural characteristics associated with specific Unicode scripts from their vast amount of training data, which may not be immediately apparent. We show that by simply inserting single non-Latin characters in a textual description, common models reflect cultural stereotypes and biases in their generated images. We analyze this behavior both qualitatively and quantitatively, and identify a model's text encoder as the root cause of the phenomenon. Additionally, malicious users or service providers may try to intentionally bias the image generation to create racist stereotypes by replacing Latin characters with similarly-looking characters from non-Latin scripts, so-called homoglyphs. To mitigate such unnoticed script attacks, we propose a novel homoglyph unlearning method to fine-tune a text encoder, making it robust against homoglyph manipulations.
PDF Abstract

 ImageNet
ImageNet
