The deterministic information bottleneck
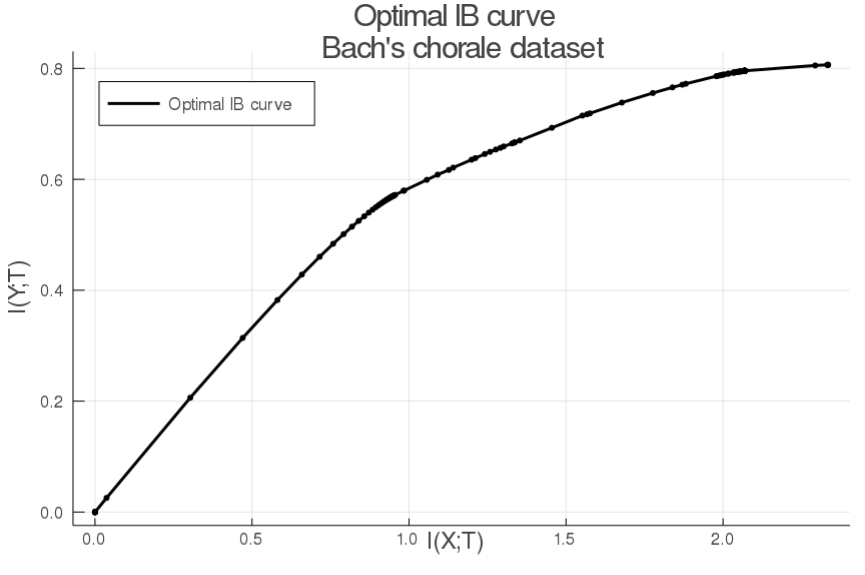
Lossy compression and clustering fundamentally involve a decision about what features are relevant and which are not. The information bottleneck method (IB) by Tishby, Pereira, and Bialek formalized this notion as an information-theoretic optimization problem and proposed an optimal tradeoff between throwing away as many bits as possible, and selectively keeping those that are most important. In the IB, compression is measure my mutual information. Here, we introduce an alternative formulation that replaces mutual information with entropy, which we call the deterministic information bottleneck (DIB), that we argue better captures this notion of compression. As suggested by its name, the solution to the DIB problem turns out to be a deterministic encoder, or hard clustering, as opposed to the stochastic encoder, or soft clustering, that is optimal under the IB. We compare the IB and DIB on synthetic data, showing that the IB and DIB perform similarly in terms of the IB cost function, but that the DIB significantly outperforms the IB in terms of the DIB cost function. We also empirically find that the DIB offers a considerable gain in computational efficiency over the IB, over a range of convergence parameters. Our derivation of the DIB also suggests a method for continuously interpolating between the soft clustering of the IB and the hard clustering of the DIB.
PDF Abstract

