The Factual Inconsistency Problem in Abstractive Text Summarization: A Survey
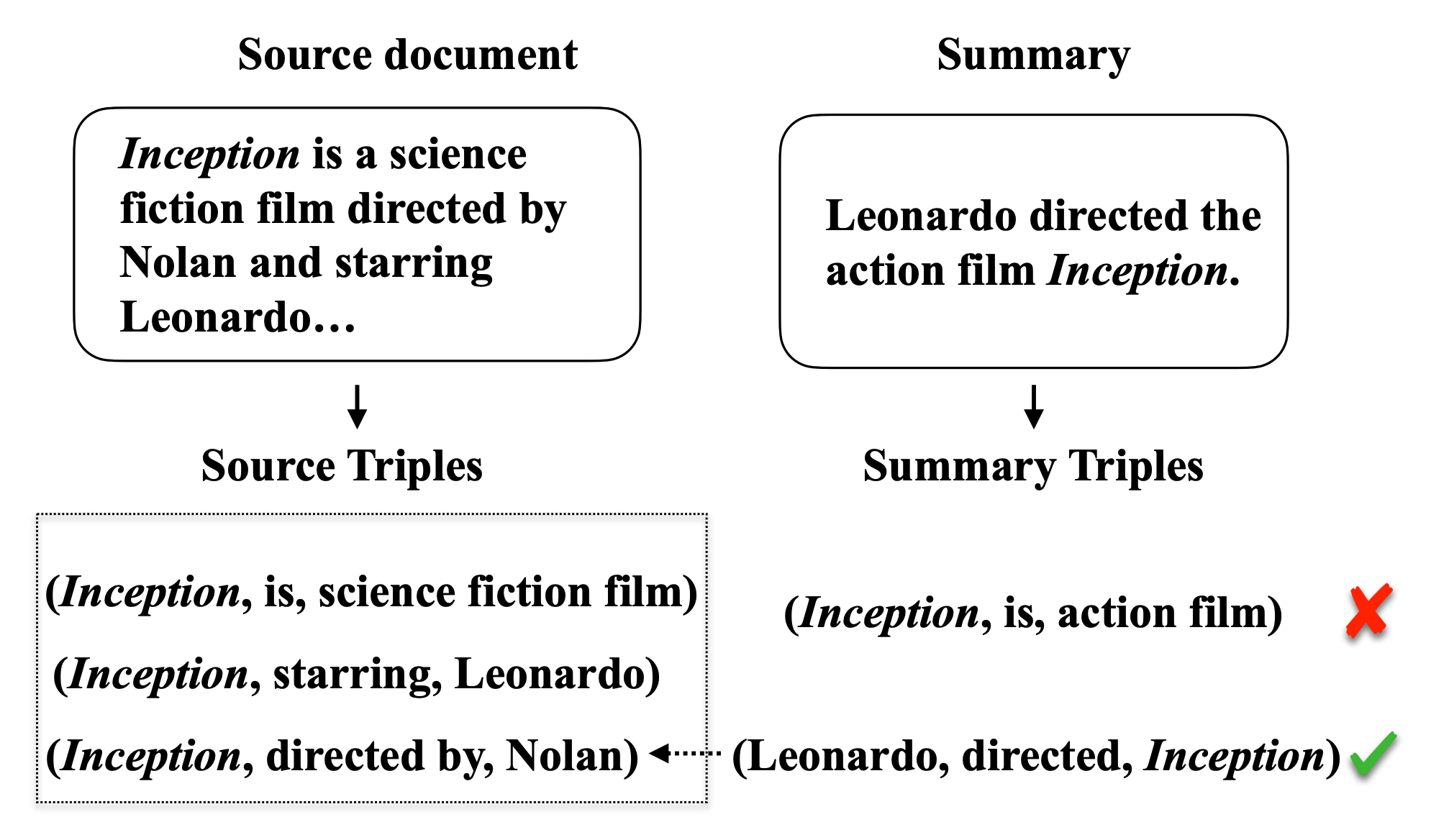
Recently, various neural encoder-decoder models pioneered by Seq2Seq framework have been proposed to achieve the goal of generating more abstractive summaries by learning to map input text to output text. At a high level, such neural models can freely generate summaries without any constraint on the words or phrases used. Moreover, their format is closer to human-edited summaries and output is more readable and fluent. However, the neural model's abstraction ability is a double-edged sword. A commonly observed problem with the generated summaries is the distortion or fabrication of factual information in the article. This inconsistency between the original text and the summary has caused various concerns over its applicability, and the previous evaluation methods of text summarization are not suitable for this issue. In response to the above problems, the current research direction is predominantly divided into two categories, one is to design fact-aware evaluation metrics to select outputs without factual inconsistency errors, and the other is to develop new summarization systems towards factual consistency. In this survey, we focus on presenting a comprehensive review of these fact-specific evaluation methods and text summarization models.
PDF Abstract

 CNN/Daily Mail
CNN/Daily Mail
