Beyond exploding and vanishing gradients: analysing RNN training using attractors and smoothness
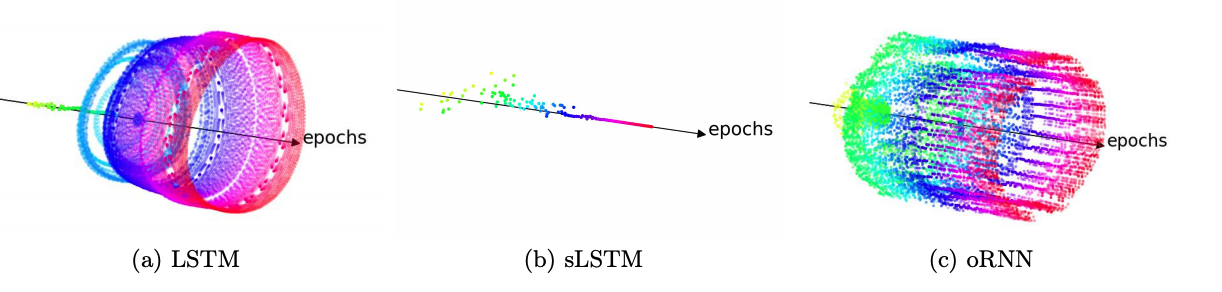
The exploding and vanishing gradient problem has been the major conceptual principle behind most architecture and training improvements in recurrent neural networks (RNNs) during the last decade. In this paper, we argue that this principle, while powerful, might need some refinement to explain recent developments. We refine the concept of exploding gradients by reformulating the problem in terms of the cost function smoothness, which gives insight into higher-order derivatives and the existence of regions with many close local minima. We also clarify the distinction between vanishing gradients and the need for the RNN to learn attractors to fully use its expressive power. Through the lens of these refinements, we shed new light on recent developments in the RNN field, namely stable RNN and unitary (or orthogonal) RNNs.
PDF Abstract
 WikiText-2
WikiText-2
