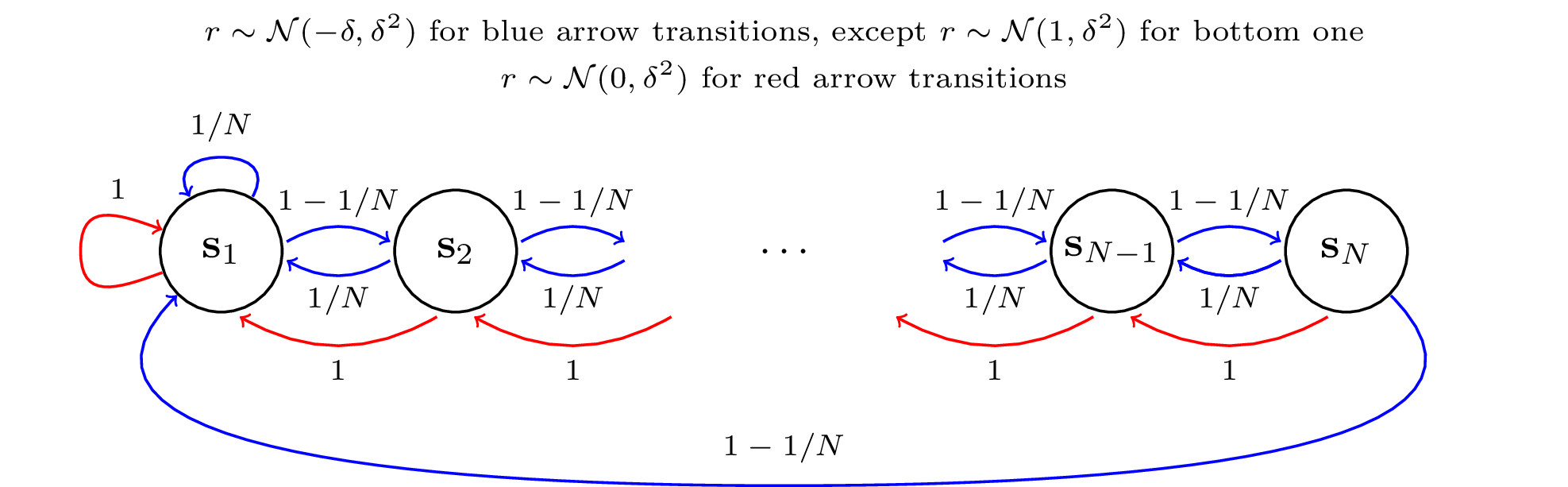
The Uncertainty Bellman Equation and Exploration
We consider the exploration/exploitation problem in reinforcement learning. For exploitation, it is well known that the Bellman equation connects the value at any time-step to the expected value at subsequent time-steps. In this paper we consider a similar \textit{uncertainty} Bellman equation (UBE), which connects the uncertainty at any time-step to the expected uncertainties at subsequent time-steps, thereby extending the potential exploratory benefit of a policy beyond individual time-steps. We prove that the unique fixed point of the UBE yields an upper bound on the variance of the posterior distribution of the Q-values induced by any policy. This bound can be much tighter than traditional count-based bonuses that compound standard deviation rather than variance. Importantly, and unlike several existing approaches to optimism, this method scales naturally to large systems with complex generalization. Substituting our UBE-exploration strategy for $\epsilon$-greedy improves DQN performance on 51 out of 57 games in the Atari suite.
PDF Abstract ICML 2018 PDF ICML 2018 Abstract